Google的E3 TTS 通过扩散模型提供高质量音频合成方法
要点:
1、E3TTS 是一种简化高效的端到端扩散式文本到语音模型,通过扩散模型生成高保真的语音波形。
2、E3TTS 模型由预训练的 BERT 模型和扩散 UNet 模型组成,以提取文本信息并迭代地生成最终的语音波形。
3、E3TTS 不仅能生成高保真音频,还支持零样本任务,如语音编辑和基于提示的生成。
Google 的研究团队提出了一种名为 E3TTS 的简便端到端扩散式文本到语音模型。该模型通过扩散模型保留时间结构,能够直接接受纯文本输入并生成音频波形。它利用预训练的 BERT 模型提取文本信息,并通过扩散 UNet 模型迭代地生成最终的语音波形。相比其他现有的文本到语音系统,E3TTS 简化了部署、训练和设置过程,并且不依赖中间特征的质量。
E3TTS 模型采用非自回归方式,以文本作为输入,实时生成音频波形。它的架构包括两个主要模块:预训练的 BERT 模型用于提取输入文本的相关信息,扩散 UNet 模型用于处理 BERT 输出,迭代地优化初始噪声波形以预测最终的原始波形。这种设计使得 E3TTS 能够直接从 BERT 特征生成高质量的音频波形,并且可以使用多种语言进行训练。
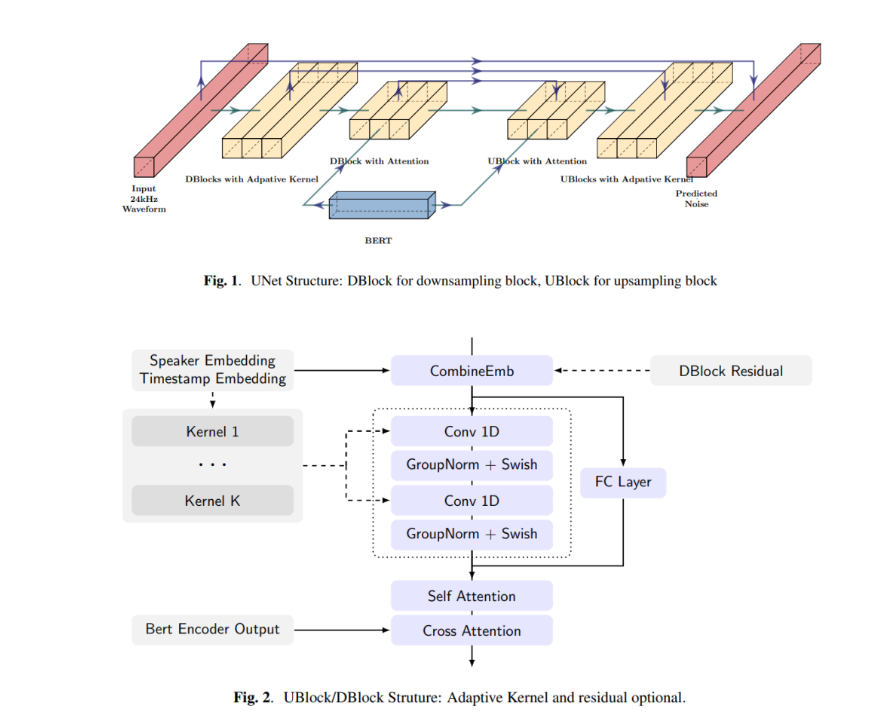
为了增强对 BERT 输出的信息提取,E3TTS 模型采用了 U-Net 结构,其中包含一系列下采样和上采样块。在顶层的下采样 / 上采样块中,引入了交叉注意力机制。在较低层次的块中,使用了自适应 softmax 卷积神经网络(CNN)内核,其内核大小由时间步和说话者确定。在其他层次中,通过特征级线性调制(FiLM)将说话者和时间步嵌入进行组合,包括用于通道级缩放和偏差预测的复合层。
实验证明,E3TTS 能够生成高保真音频,接近最先进的神经 TTS 系统的性能。此外,它还支持各种零样本任务,如语音编辑和基于提示的生成。E3TTS 的设计简化了端到端 TTS 系统的构建,并在实验中取得了令人印象深刻的结果。
总结起来,E3TTS 通过扩散模型从 BERT 特征直接生成高质量音频。它简化了端到端 TTS 系统的设计,经过实验证明具有出色的性能。


 0000
0000- 0000
- 0000
 0003
0003- 0000