AI「脑补」画面太强了!李飞飞团队新作ZeroNVS,单个视图360度全场景生成
近来,利用3D感知扩散模型训练模型,然后对单个物体进行SDS蒸馏的研究数不胜数。
但是,能够真正做到「场景级」的画面生成,从未实现。
现如今,斯坦福李飞飞和谷歌团队打破了这个记录!
比如,输入一张从某个角度拍摄的客厅图片,整个客厅的样貌就出来了。

再来一张角度很偏的屋子拐角图,也能生成一个意想不到的空间。

还有各种物体室内、户外的全场景图。

看到这儿,不得不不让人惊呼AI「脑补」简直强的一批!
那么,这究竟是如何实现的呢?
3D感知扩散模型——ZeroNVS
最新论文中,斯坦福和谷歌研究人员引入了一种3D感知扩散模型——ZeroNVS。

论文地址:https://arxiv.org/pdf/2310.17994.pdf
单图像、360度新视图合成 (NVS) 的模型,在生成图像时应该逼真且多样化。
合成图像对于我们来说,应该看起来自然且3D一致,并且它们还应该捕获不可观察区域的许多可能的解释。
以往,这个具有挑战性的问题,通常是在单个物体,甚至没有背景下研究的,也就是说,对真实性和多样性的要求都被简化了。
最近的研究依赖于高质量大规模数据集,比如Objaverse-XL,使得条件散射模型能够从新视角产生逼真图像,然后通过SDS蒸馏采样,以提高3D一致性。
同时,由于图像多样性主要体现在背景中,而不是物体中,因此对背景的无知显着降低了合成多样化图像的效果。
事实上,大多数以物体对象为中心的方法,不再将多样性视为衡量标准。
然而,在复杂真实场景生成新视角合成是一个更难的问题,目前还没有包含完整场景真值信息的大规模数据集。
研究人员在研究中对背景进行了建模,以产生多样的结果。
在ZeroNVS中,作者开发了新技术来预测单个真实图像的场景,并且建立在之前在3D感知扩散模型训练(Zero-1-to-3)和SDS蒸馏(DreamFusion)方面的工作基础上。
具体方法
研究人员着手从单个真实图像合成场景级新颖视图的问题。
与之前的工作类似,我们首先训练扩散模型
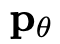
来执行新颖的视图合成,然后利用它来执行3D SDS蒸馏。
与之前的工作不同地方在于,作者关注的是场景而不是物体。
场景提出了一些独特的挑战。首先,先前的研究使用摄像机和比例的表示,这些表示对于场景来说要么含糊不清,要么表达力不足。
其次,先前研究的推理过程是基于 SDS 的,它具有已知的模式崩溃问题,并且通过大大减少预测视图中的背景多样性在场景中体现出来。
与之前的工作相比,研究人员尝试了通过「改进场景的表示」和「推理程序」来应对这些挑战。
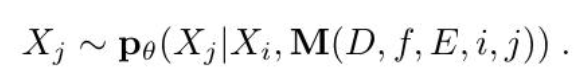
在这个公式中,M的输出,和单个图像的输入
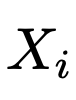
是模型可用于视图合成的唯一信息。
表示视图综合的对象
如下图,3DoF相机姿势捕获指向原点的相机的相机仰角、方位角和半径,但无法表示相机的滚动(如图)或空间中任意方向的相机。
具有这种参数化的模型无法在现实世界数据上进行训练,其中许多相机姿势不能用3DoF姿势充分表示。
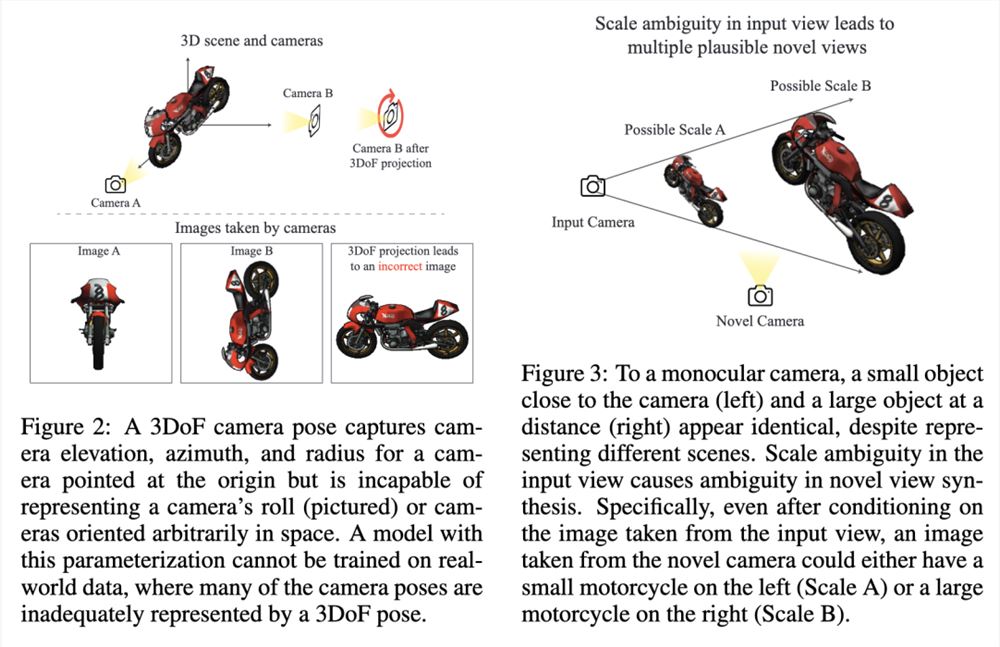
表示视图合成的通用场景
对于场景,研究人员应该使用具有6个自由度的相机表示,可以捕获所有可能的位置和方向。
捕获六个自由度的相机参数化的一种直接选择是相对位姿参数化。研究人员建议还将视野作为额外的自由度,并将这种组合表示称为「6DoF 1」。
M6DoF 1的一个吸引人的特性是它对于场景的刚性变换具有不变性,因此可以得到:
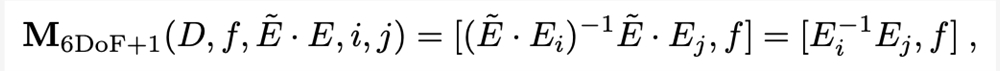
对于每个归一化方案,ZeroNVS中多个样本的Sobel边缘图方差的热图。研究者提出的方案M6DoF 1,观察者减少了由于尺度模糊而导致的随机性。

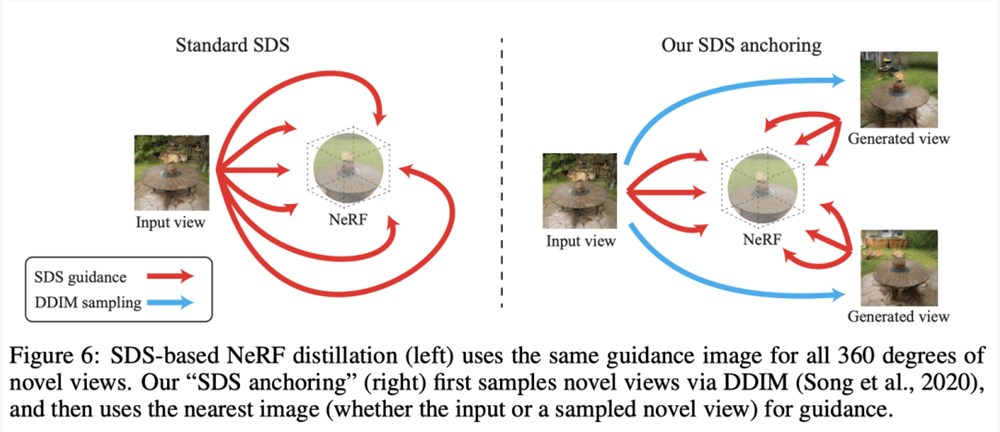
通过SDS anchoring提高多样性
基于SDS的NeRF蒸馏(左)对所有360度新视图使用相同的引导图像。
作者的「SDS anchoring」(右)首先通过DDIM对新视图进行采样,然后使用最近的图像(无论是输入还是采样的新视图)作为指导。
实验结果
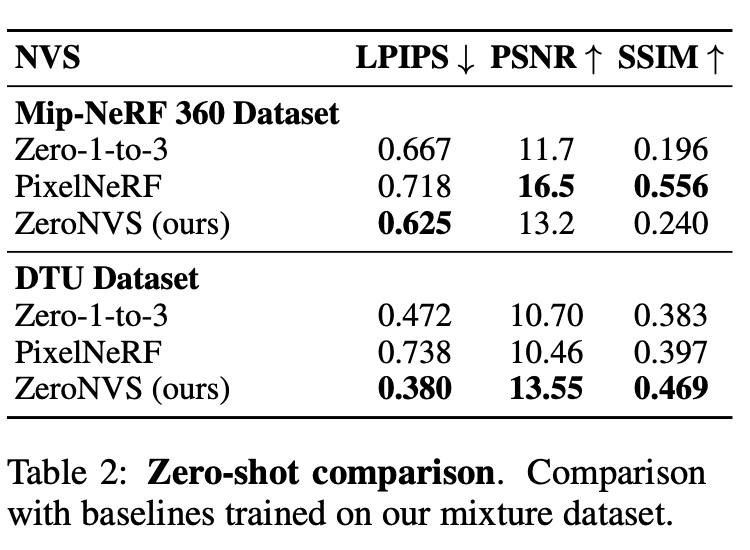
再具体评估中,研究人员使用了一组标准的新视图合成指标来评估所有方法:PSNR、SSIM和LPIPS。
由于PSNR和SSIM有已知缺点,研究人员更看重LPIPS,并确认PSNR和SSIM与问题设置中的性能没有很好的相关性,如图7所示。

结果如表1所示。
首先与基线方法 DS-NeRF、PixelNeRF、SinNeRF、DietNeRF进行比较。
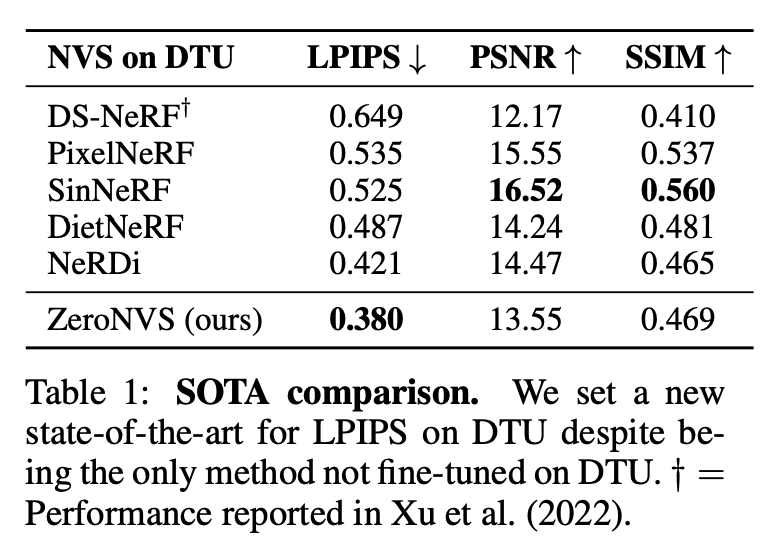
尽管所有这些方法都是在DTU上进行训练的,但研究人员从未在DTU上进行过训练,但实现了最先进的LPIPS零样本。
图8中显示了一些定性比较。

DTU场景仅限于相对简单的前向场景。
因此,研究人员还引入了一个更具挑战性的基准数据集,即Mip-NeRF360数据集,来对单张图像的360度视图合成任务进行基准测试。
研究人员使用这个基准作为零样本基准,并在混合数据集上训练3个基线模型来比较零样本性能。
限制这些零样本模型,其方法在该数据集的LPIPS上遥遥领先。在DTU上,新方法在所有指标上都超过了Zero-1-to-3和零样本PixelNeRF模型,而不仅仅是LPIPS,如表2所示。
作者介绍
Kyle Sargent
斯坦福大学的一名博士生,从2022年秋季开始,在斯坦福人工智能实验室工作,导师是Jiajun Wu和李飞飞。
他还曾在谷歌研究院担任学生研究员。
- 0000
- 0000
- 0000
- 0000
- 0000