超强大模型DEJAVU 推理速度是FasterTransformer的2倍
要点:
DEJAVU 是一个系统,采用一种经济高效的算法,结合异步和硬件感知实施,动态预测每一层的上下文稀疏性,从而提高大型语言模型(LLM)的推断速度。
研究团队通过引入上下文稀疏性的概念,动态修剪特定的注意力头和MLP参数,而无需改变预训练模型,以提高LLM在具有严格延迟约束的应用中的效率。
DEJAVU 通过硬件感知的稀疏矩阵乘法实施,显著降低了开源LLM(如OPT-175B)的延迟,超过了Nvidia的FasterTransformer库,并在小批量大小下超过了广泛使用的Hugging Face实现。
大型语言模型(LLM),如GPT-3、PaLM和OPT,以其卓越的性能和能够在上下文中学习的能力,令人叹为观止。然而,它们在推断时的高成本是它们的显著缺点。为了解决这一挑战,研究团队提出了DEJAVU系统,该系统采用了一种经济高效的算法,结合异步和硬件感知的实施,动态预测每一层的上下文稀疏性,从而提高LLM的推断速度。
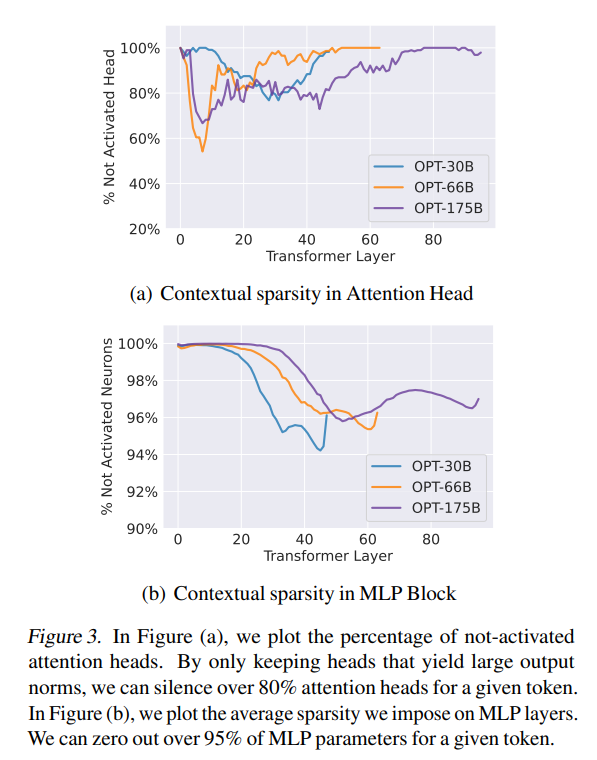
为了定义适用于LLM的理想稀疏性,研究团队提出了三个关键标准:不需要模型重新训练、保持质量和上下文学习能力以及提高现代硬件上的时钟时间速度。为了满足这些要求,他们引入了上下文稀疏性的概念,该概念包括产生与给定输入几乎相同结果的小型、依赖于输入的注意力头和MLP参数的子集,而无需完全模型。DEJAVU利用上下文稀疏性,使LLM在具有严格延迟约束的应用中更加高效。
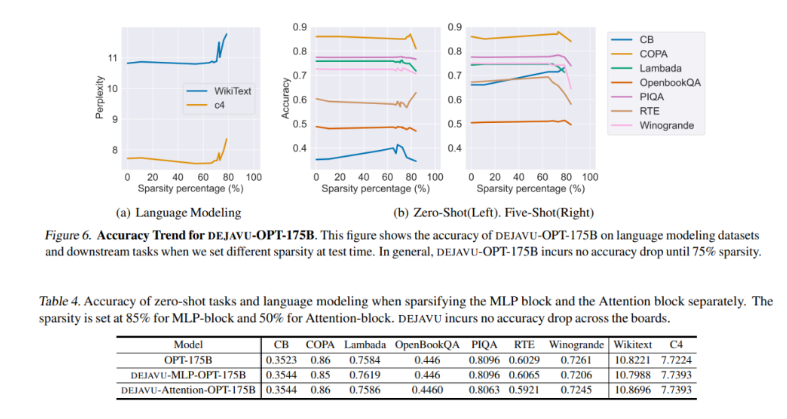
具体来说,研究人员提出了一种低成本的、基于学习的算法,用于实时预测稀疏性。给定特定层的输入,该算法预测后续层中的相关注意力头或MLP参数的子集,并仅为计算加载它们。他们还引入了一种异步预测器,类似于经典的分支预测器,以减少顺序开销。通过引入硬件感知的稀疏矩阵乘法实施,DEJAVU显著降低了开源LLM(如OPT-175B)的延迟。它在端到端延迟上超过了Nvidia的FasterTransformer库,而在小批量大小下也超过了广泛使用的Hugging Face实现。
这项研究表明,DEJAVU有效地利用了异步前瞻预测器和硬件高效稀疏性,以提高LLM的时钟时间推断。这些有前途的实验结果突显了上下文稀疏性在显著减少推断延迟方面的潜力,相较于现有模型,这项研究使LLM更容易被更广泛的AI社区使用,可能开启令人兴奋的新的AI应用。


 0001
0001
 0000
0000- 0000
- 0000
- 0000