苹果研究人员推出Ferret:一种用于高级图像理解和描述突破性多模态语言模型
划重点:
1. 研究困难:语言学习中的地理信息和语义知识融合展开,提出Ferret模型解决引用和定位问题
2. Ferret模型:采用MLLM为基础的Ferret模型,具备强大的全局理解能力,可同时处理自由文本和引用区域,性能领先传统模型。
3. 应用前景:文章指出Ferret模型可应用于日常交流中,提供了一种新的多模式语言模型,为图像理解和描述领域带来突破性进展。
研究人员在最新的一项研究中介绍了Ferret,这是一款多模式语言模型,旨在实现高级图像理解和描述。该研究聚焦于视觉-语言学习中的关键问题,即如何融合地理信息和语义知识,以便模型能够同时引用和定位图像中的元素。研究指出,引用和定位是两项关键的能力,前者要求模型理解语义描述,后者要求模型在图像中定位相关区域。
为了解决这一问题,哥伦比亚大学和 Apple 的研究人员提出了Ferret模型,这是一款基于MLLM(多模式大语言模型)的新型模型,具备强大的全局理解能力。
Ferret模型的关键特点在于它可以同时处理自由文本和引用区域。它采用了一种混合区域表示方法,结合了离散坐标和连续视觉特征,以处理不同形状的区域,如点、框、涂鸦和复杂多边形。这种灵活性使Ferret能够更准确地理解和描述图像中的元素,提高了人机交互的全面性。
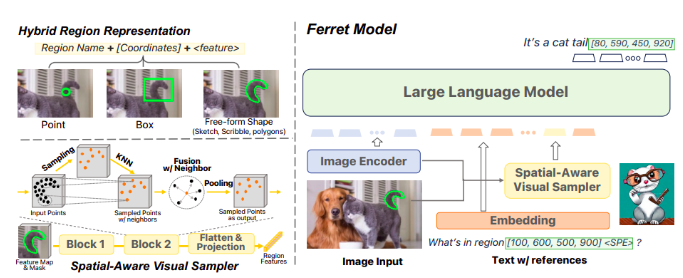
为了训练Ferret模型,研究人员创建了GRIT(Ground-and-Refer Instruction-Tuning)数据集,其中包括1.1百万个样本,用于指导模型进行引用和定位。该数据集包含了不同层次的空间知识,包括区域描述、连接、物体和复杂的推理。通过精心设计的模板,大部分数据从当前的视觉-语言任务中转化而来,如对象识别和短语定位,以用于指导模型。
研究人员还利用ChatGPT/GPT-4等工具,收集了34,000多个引用和定位对话,以帮助模型进行训练。他们还进行了空间感知的负数据挖掘,以增强模型的鲁棒性。Ferret模型表现出高度的开放式空间感知和定位能力,能够在引用和定位任务上表现优于传统模型。此外,研究人员认为引用和定位能力应该融入日常人机交流中,以实现更广泛的应用。
为了评估Ferret模型的性能,研究人员创建了Ferret-Bench,包括三种新类型的任务:引用描述、引用推理和对话中的定位。他们将Ferret与目前使用的最佳MLLM模型进行比较,发现Ferret的性能平均优于它们20.4%。此外,Ferret还具有减少对象幻觉的显著能力。
Ferret模型,它具备了在MLLM中进行精细和开放式引用和定位的能力。Ferret采用了一种混合区域表示方法,配备了独特的空间感知视觉采样器。此外,他们创建了GRIT数据集,用于模型训练,并评估了Ferret在不同任务中的性能。这一研究为多模式语言模型领域带来了突破性进展,为图像理解和描述提供了新的可能性。
项目网址:https://github.com/apple/ml-ferret
论文网址:https://arxiv.org/abs/2310.07704v1
- 0000
- 0000
- 0000
- 0000
- 0000