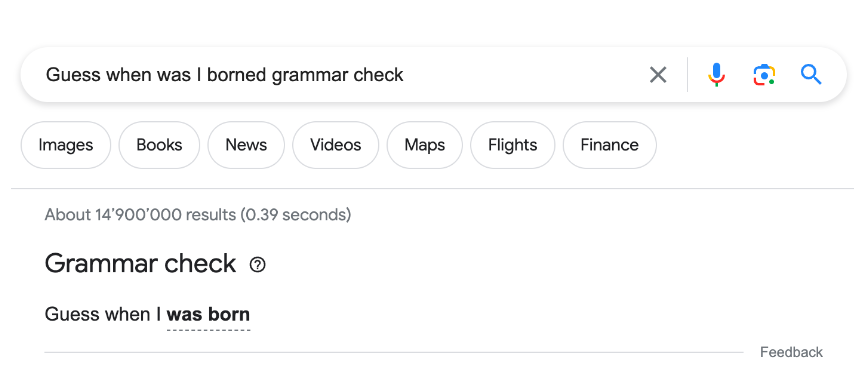
谷歌搜索引入语法检查模型EdiT5 提高语法纠正准确性
💡 划重点:
- Google研究团队开发了一种高效的语法纠正模型,基于EdiT5架构,使用户能够在Google搜索中检查查询的语法。
- 这一模型采用了新颖的文本编辑方法,降低了解码延迟,提高了纠正的准确性,同时结合了大型语言模型(LLMs)的优点。
Google的研究团队最近开发了一种高效的语法检查模型,它将语法检查引入了Google搜索,为用户提供了一种在查询语法方面的辅助工具。这一模型基于EdiT5架构,通过新颖的文本编辑方法,极大地减少了解码延迟,提高了语法纠正的准确性。
传统的语法错误纠正(GEC)方法通常将其视为翻译问题,并使用自回归变换器模型逐个标记解码响应,条件是以前生成的标记。然而,这种方法的效率较低,因为解码不能并行进行。文章指出,通常只需要对输入文本进行少量修改,因此可以将GEC视为文本编辑问题,仅使用自回归解码器生成修改,从而显著降低GEC模型的延迟。
EdiT5模型基于T5变换器编码器-解码器架构,采用了一些关键的修改。它使用编码器来确定要保留或删除的输入标记,这些保留的标记构成了初步的输出。此后,解码器输出缺失的标记,并使用指针机制指示每个新标记的放置位置,以生成语法正确的输出。与传统的GEC方法相比,解码器只运行少量步骤,从而提高了效率。
为了降低解码器延迟,研究团队将解码器减少到单层,并通过增加编码器的大小来进行补偿。实验结果表明,EdiT5大型模型相比具有248M参数的T5基础模型,提供了9倍的速度提升,同时提高了修正的准确性。EdiT5模型的平均延迟仅为4.1毫秒。

此外,研究团队还介绍了如何使用大型语言模型(LLMs)的优点,结合EdiT5的低延迟,通过硬蒸馏技术训练了教师LLM,用于生成学生EdiT5模型的训练数据。他们还详细解释了如何生成更干净和一致的训练数据,并通过自训练和迭代改进等技术提高了数据的质量。
他们开发了两种基于EdiT5的模型,分别用于语法错误校正和语法分类。在使用语法检查功能时,查询首先经过校正模型,然后通过分类模型检查输出是否确实正确。这种分离的分类模型有助于更容易在精度和召回率之间进行权衡,并减少了为模糊或无意义的查询提供错误或混乱校正的风险。
谷歌的这一语法检查功能基于EdiT5模型架构,为用户提供了一种检查其查询语法的有效方式,进一步提升了Google搜索的用户体验。
- 0000
- 0004
 0001
0001- 0003
- 0000



