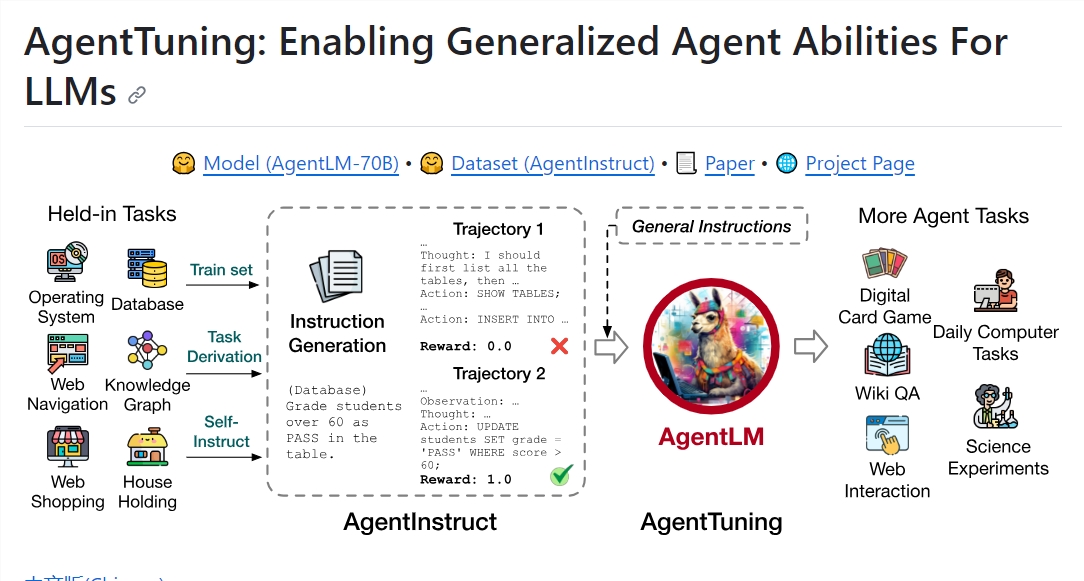
AgentTuning:通过多智能体任务调整语言模型
最近,研究人员在 GitHub 上开源了一个名为 AgentTuning 的项目。该项目提供了一种新的方法来调整语言模型,通过多个智能体任务中的交互轨迹来训练和调整语言模型,以更好地适应不同的任务和场景。
这种方法可以提高语言模型的效果和泛化能力,同时减少手动调整的工作量。AgentTuning 已经在对话生成、问答系统、摘要生成等多个自然语言处理任务中得到了验证。需要注意的是,这种方法不仅适用于语言模型,也适用于其他类型的模型。
项目地址:https://github.com/THUDM/AgentTuning
主要功能:
AgentInstruct数据集:AgentInstruct是一个经过精心筛选的数据集,包括1,866个高质量互动场景,旨在提升AI代理在6个不同的现实世界任务中的性能。这些场景覆盖了从日常家庭事务到数据库操作的6个不同领域,具有5到35个平均回合数,确保了多样性和复杂性。
AgentLM模型:AgentLM模型是通过对AgentInstruct数据集和Llama2-chat系列的ShareGPT数据集进行混合训练而创建的。这些模型遵循Llama-2-chat的对话格式,其中系统提示已固定为“您是一个有帮助、尊重和诚实的助手”。AgentLM提供了7B、13B和70B模型,可以在Huggingface模型库上获取。
快速部署:AgentTuning使用文本生成推理技术加速评估过程,用户可以轻松地启动AgentLM-70B实例,并在端口30070上访问客户端。这使得用户能够快速生成文本响应。
全面的评估:AgentTuning提供了6个“持有”任务和6个“持有外”任务的详细评估信息,以验证AgentLM的性能。这些任务来自不同的框架,包括SciWorld、MiniWoB 、HotpotQA、ReWOO、WebArena和数字卡牌游戏,涵盖了各种任务类型。
引用支持:如果用户发现AgentTuning的工作对他们有用,他们可以引用相关论文,为团队的努力提供支持。
总的来说,AgentTuning是一个具有巨大潜力的项目,为改善LLMs的通用智能能力提供了重要的工具和资源。通过AgentInstruct数据集和AgentLM模型,用户可以在各种现实世界任务中获得更强大的AI代理,同时保持良好的通用语言能力。
 0000
0000- 0000
- 0003
- 0000
- 0000