Google发布PaLI-3视觉语言模型,性能相当于体积大10倍的模型
📌划重点:
Google Research和Google DeepMind发布了PaLI-3,这是一款仅有50亿参数的视觉语言模型(VLM)。
尽管相对较小,PaLI-3在多模态测试中超越了体积大10倍的模型,可以回答关于图像的问题、描述视频、识别对象和读取图像上的文本。
尽管规模较小,PaLI-3的性能表现卓越,这归功于对SigLIP方法的对比预训练视觉转换器的应用。小型模型更适合培训和部署,更环保,并允许更快的模型设计研究周期。
Google Research和Google DeepMind日前发布了名为PaLI-3的新一代视觉语言模型(VLM),尽管仅拥有50亿参数,但其性能令人瞩目。与体积大10倍的竞争对手相比,PaLI-3在多模态测试中表现出色,能够回答关于图像的问题、描述视频、识别对象和读取图像上的文本。
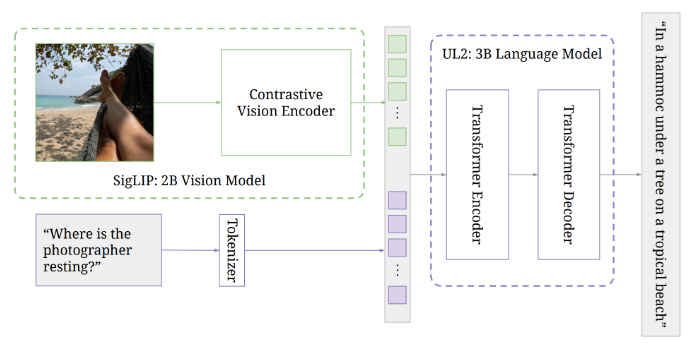
通常情况下,VLM由预训练的图像模型和语言模型组成,后者已经学会将文本与图像相关联。PaLI-3的架构遵循了其前身的先例,包括一个将图像编码为标记的视觉转换器,这些标记连同文本输入一起传递给一个编码器-解码器转换器,产生文本输出。
Google此前已经展示,高度扩展的视觉转换器并不一定会对仅涉及图像的任务(如ImageNet)产生更好的结果,但对于回答有关图像的问题等多模态任务,它可以取得显著的性能提升。随着PaLI-X的推出,Google将模型规模扩大到了550亿参数。
与PaLI-X相比,PaLI-3采用了一种新的训练方法,使用了对比预训练的视觉转换器(SigLIP),类似于CLIP。该视觉转换器仅拥有20亿参数,与语言模型一起,PaLI-3仅有50亿参数。
这种小型模型更适合培训和部署,对环境更友好,并允许更快的模型设计研究周期。令人印象深刻的是,尽管规模相对较小,PaLI-3在超过10个图像转语音测试中与今天的最佳VLM表现相媲美,而且在没有经过视频数据训练的情况下,在需要回答关于视频的问题的测试中也取得了新的最佳成绩。
虽然小型模型具有巨大的潜力,但模型领域的趋势似乎将朝着更大型模型的方向发展。不过,正是PaLI-3在其体积相对较小的情况下表现出色,彰显了SigLIP方法在未经结构化的多模态数据上进行视觉转换器训练的潜力。考虑到这种未经结构化的多模态数据的可用性,Google可能很快会推出更大版本的PaLI-3。
该研究团队表示,PaLI-3的性能表现,尽管仅有50亿参数,重新激发了对复杂VLM核心组成部分的研究兴趣,并有望推动新一代大规模VLM的发展。
项目网址:https://github.com/kyegomez/PALI3
- 0001
- 0000

 0000
0000- 0001
- 0000


