RingAttention:一种降低Transformer内存需求的新AI技术
划重点:
1. Transformer模型在处理长序列时面临的内存需求挑战,UC伯克利研究人员提出的RingAttention方法。
2. RingAttention通过将自注意力和前馈网络计算块块地分布在多个设备上,实现了内存高效,允许训练超过500倍长度的序列。
3. RingAttention的潜在应用领域,包括大型视频-音频-语言模型和理解科学数据。
UC伯克利的研究人员提出了一项名为RingAttention的新方法,以解决深度学习模型中内存需求的挑战。在最新的研究中,研究人员探讨了Transformer模型在处理长序列时面临的问题,特别是由于自注意力机制引发的内存需求。这一问题已经成为了在人工智能领域中提高模型性能的一个重要挑战。
Transformer模型是一种在自然语言处理等领域取得了重大突破的深度学习架构。它基于自注意力机制,可以在进行预测时权衡输入序列的不同部分的重要性。然而,随着输入序列长度的增加,内存需求呈二次增长,这导致了在处理长序列时的挑战。
UC伯克利的研究人员提出了RingAttention方法,通过将自注意力和前馈网络计算分块进行,可以将输入序列分布到多个设备上,从而实现内存高效。这一方法的关键思想是将计算块块块地分布在多个设备上,同时保持内存消耗与块大小成比例。这意味着每个设备的内存需求与原始输入序列长度无关,从而消除了设备内存的限制。
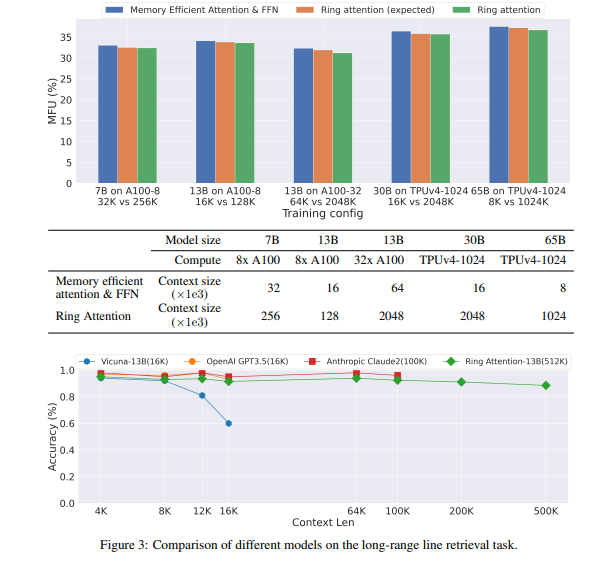
研究人员的实验证明,RingAttention可以将Transformer模型的内存需求降低,使其能够训练比以前的内存高效方法长500倍以上的序列,而不需要对注意力机制进行近似。此外,RingAttention还允许处理长度超过1亿的序列,为处理大规模数据提供了可能性。
尽管这项研究仅涉及方法的有效性评估,而未进行大规模训练模型,但这一方法的性能取决于设备数量,因此还需要进一步的优化。研究人员表示,他们将来计划在最大序列长度和最大计算性能方面进行更多研究,这将为大型视频-音频-语言模型、利用扩展反馈和试验错误学习、代码生成和理解科学数据等领域提供激动人心的机会。
论文网址:https://arxiv.org/abs/2310.01889
- 0000
- 0000
- 0000

 0003
0003- 0000