ReMax算法带来解决方案!RTX 4090限制下 提高大模型使用RLHF效率
要点:
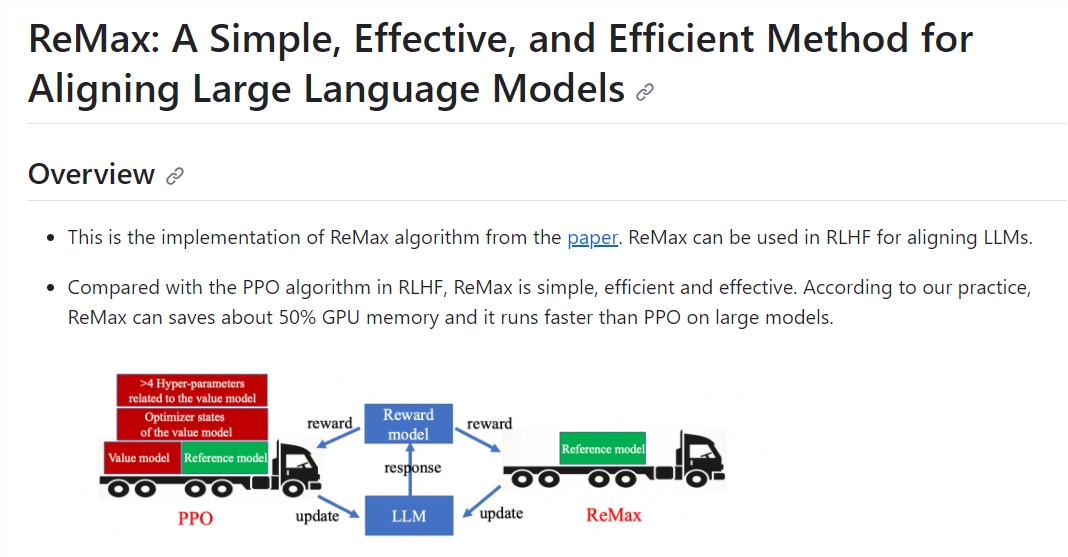
ReMax算法的关键思想:ReMax是专门为RLHF任务设计的算法,与通用RL算法PPO不同。它利用三个特性,包括快速模拟、确定性转移和轨迹级奖励,来构建梯度估计器,从而显著减少计算开销。
算法的优势:ReMax相对于PPO有很多优势,包括实现简易、少量超参数、节省约50%内存、提高训练速度。这使得ReMax在大型模型上的应用更加高效。
ReMax的性能:研究表明,在不同任务中,ReMax能够与PPO一样有效地最大化奖励,同时显著减少GPU内存使用,并提高训练速度。这对大型语言模型的发展具有重要意义。
在RTX4090被限制的时代下,一种名为ReMax的全新算法为大型模型在基于人类反馈的强化学习(RLHF)任务中带来了高效性的解决方案。这篇文章介绍了ReMax算法,它的作者是李子牛、许天、张雨舜、俞扬、孙若愚和罗智泉。ReMax算法的目标是降低计算成本,同时提高性能。
今年,大型语言模型(LLMs)如ChatGPT等在各个领域获得了广泛的应用,但这也引发了对计算资源,尤其是GPU的巨大需求。监督训练地调优一个Llama2-7B模型需要80GB以上的内存,而为了与人类对齐,LLMs还需要进行RLHF的训练,这导致GPU消耗是SFT的2倍以上,训练时间可能是SFT的6倍以上。
项目地址:https://github.com/liziniu/ReMax
论文链接:https://arxiv.org/abs/2310.10505
近日,美国政府对英伟达GPU产品H100、H800等在中国市场的限制措施使中国的大型语言模型和人工智能领域面临更大的挑战,因此减小RLHF的训练成本对LLMs的发展至关重要。
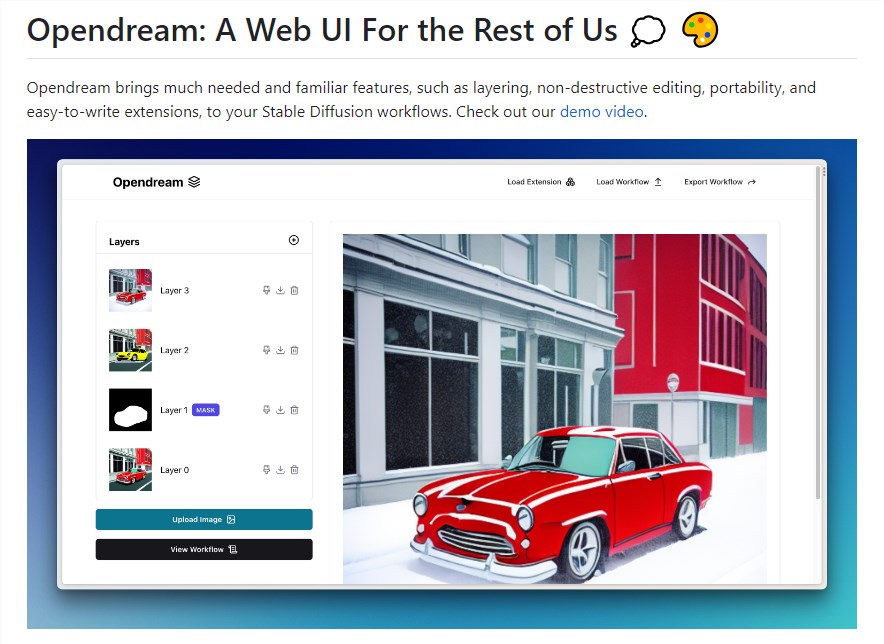
ReMax算法的动机在于解决RLHF的计算开销问题,尤其是第三阶段,即奖励最大化阶段。现有的RL算法PPO是通用的,但不够适用于RLHF任务,因为它使用了价值模型,该模型增加了存储需求,导致计算开销巨大。
ReMax的思路是设计一种专门为RLHF任务优化的算法,通过观察RLHF的特点,发现RLHF中不需要价值模型,因此将其移除,以降低计算成本。
ReMax算法基于古老的策略梯度算法REINFORCE,但通过使用贪婪生成的回答的奖励作为基准值,它有效地解决了REINFORCE算法中的高方差问题,提高了模型训练的效果。ReMax算法的优势在于其简洁性,核心部分仅需6行代码,相较于PPO,减少了超参数的数量和内存的使用。
通过实验,ReMax在不同任务中能够像PPO一样有效地最大化奖励,同时能够节省近50%的GPU内存,提高训练速度。
总而言之,ReMax算法为RLHF任务提供了一种高效的解决方案,通过减小计算开销,提高了大型语言模型的性能。它具有潜在的通用性,可以应用于其他自然语言处理任务,同时也有望应对硬件资源的限制。这一算法为大型模型的发展开辟了新的道路,有望在未来的研究和应用中发挥关键作用。
- 0005
- 0000
- 0000


 0001
0001- 0000