PyTorch大更新,编译代码速度暴增35倍!视觉模型一键部署,头显Quest 3可用
【新智元导读】最近,在Pytorch发布会上,发布移动端Pytorch解决方案ExecuTorch,实现在移动端设备上大范围地部署AI工具,并推出最新版本Pytorch2.1,推理速度大幅提升。
在刚刚召开的PyTorch大会上,PyTorch发布了一大波更新,把深度学习从业者们高兴坏了!

正式推出ExecuTorch。它可以让PyTorch在Arm、苹果和高通的处理器上运行,实现在移动端设备上大范围地部署AI工具。
伴随着这个更新,在可以预见的未来,手机,VR头显,汽车和可穿戴等移动设备将会全面AI化。
除此之外,Pytorch还宣布,torch.compile实现了对NumPy代码跟踪的支持,从而可以利用PyTorch的编译器生成高效的融合矢量化代码,而无需修改原始NumPy代码。
更重要的是,这次更新还允许通过在torch.device("cuda")下运行torch.compile来在CUDA上执行NumPy代码!
深度学习大佬Sebastian也证实,这次更新后,用PyTorch编译NumPy代码时速度暴增35倍!激动人心!
而就在前不久,PyTorch2.1也正式发布了。
这个新版本在torch.compile、torch.distributed.checkpoint中提供自动动态形状(Automatic Dynamic Shape)支持,可以在多个队列上并行保存/加载分布式训练作业,以及torch.compile对NumPy API的支持。

此外,新版本还提供了多个性能方面的改进(例如CPU电感器改进、AVX512支持、缩放点积注意力支持)以及torch.export的原型版本、健全的全图捕获机制和torch.export基于量化。
除了新品的发布,业内各路大佬都会在大会上分享关于AI模型训练,AI开源的深度见解。

ExecuTorch让AI模型部署到全平台
在这次的PyTorch Conference上,最重要的内容就是ExecuTorch的发布。
ExecuTorch是一个面向移动端的PyTorch平台,提供基础设施来运行PyTorch 程序,支持从AR/VR,可穿戴设备到标准设备上iOS和Android移动部署。
ExecuTorch的主要目标之一是实现PyTorch程序更广泛的定制和部署功能。
官方宣称这套工具使机器学习开发人员能够用更加高效的方式对各种平台上的模型进行分析和调试。

PyTorch的联合创始人Soumith Chintala称:
ExecuTorch让PyTorch能够支持移动和其他边缘设备。它将为开发人员提供一条以前不存在的发展方向,能让这些设备进行小规模,高性能的运算,并让整个社区成员都能在这些设备上加速部署自己的程序,实在是令人兴奋!
ExecuTorch让深度学习开发人员能够以组件化的方式,在各种计算平台上从头构建自己的应用,在3个方面体现出了非常强的优势:
无与伦比的便携性
与各种计算平台兼容,从性能最强劲的手机到嵌入式系统都将获得支持。
令人赞叹的生产力
使开发人员能够使用相同的工具链和SDK,在各种平台上实现PyTorch模型的设计,调试以及部署,从而大大提高生产力。
前所未有的性能表现
由于任务执行时间比较短,并且可以利用完整硬件功能(包括通用CPU和专用处理器,例如NPU和DSP)和能力,最终就可以为用户提供无缝和高性能的体验。
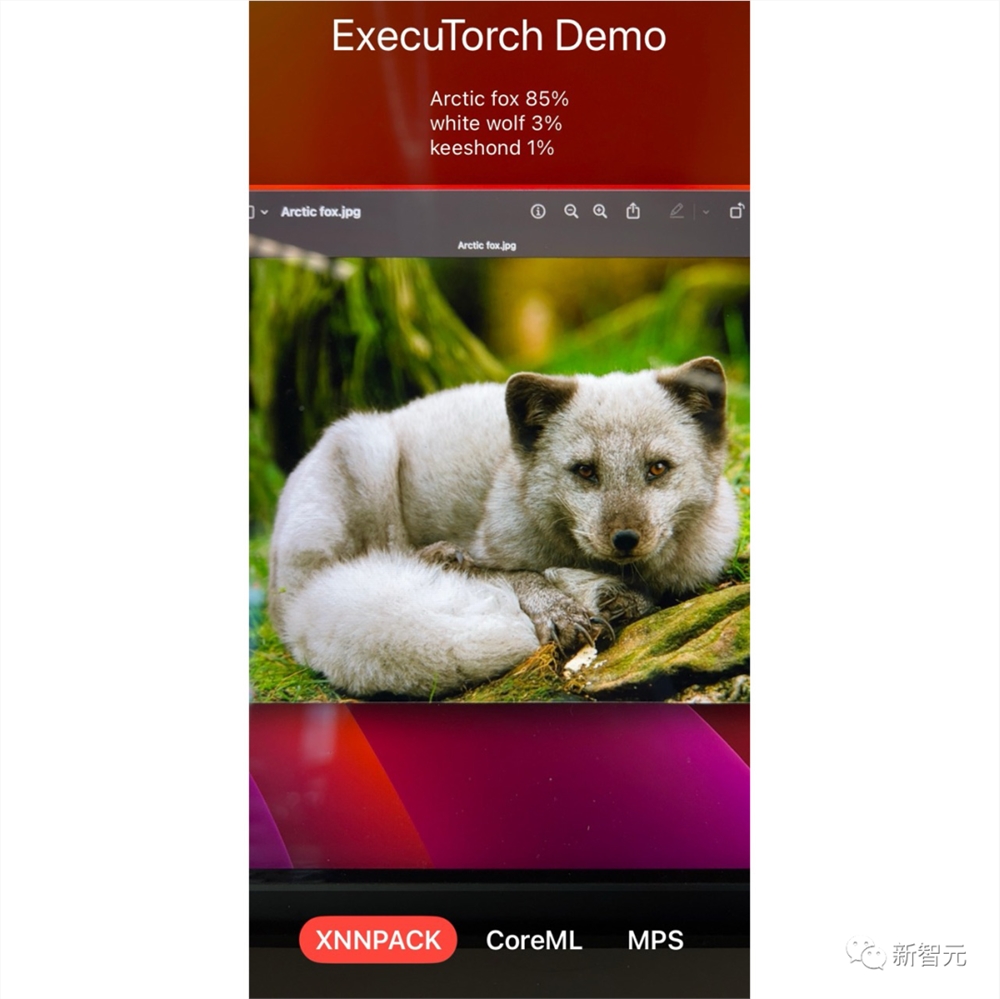
在官方提供的Demo中,我们可以看到,在移动端,可以轻松部署深度学习的视觉模型。
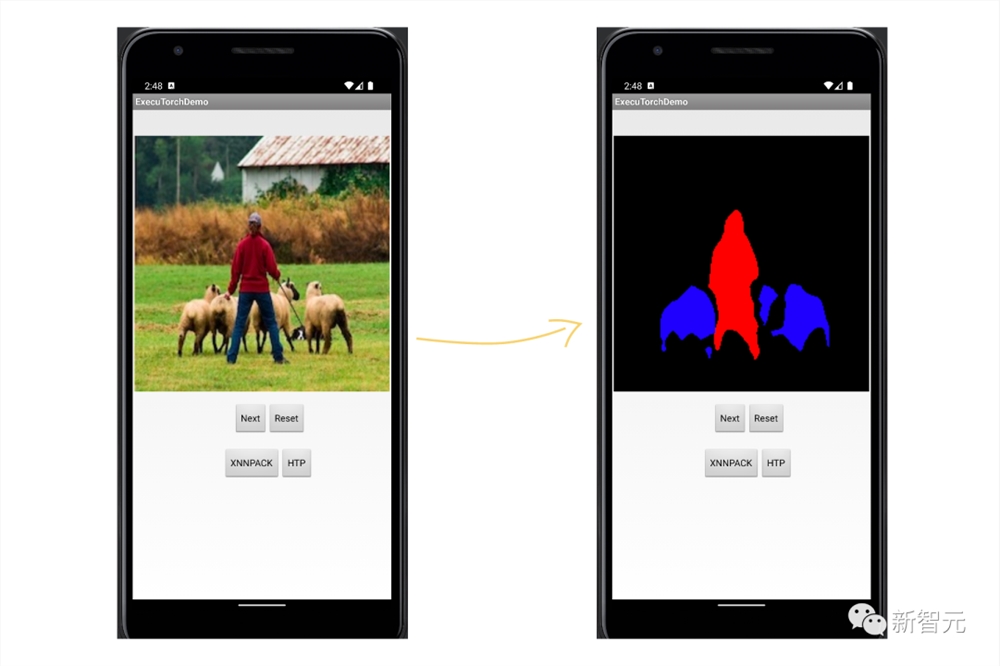
如下图,可以在终端对图像进行语义分割,分割的效果虽然比不上使用GPU推理的结果,但是相信随着终端硬件的发展,其图像处理效果会有进一步的提升。
Meta已经对这项技术进行了验证,将其应用于最新一代VR头显Quest3当中。

在PyTorch大会的主题演讲中,Meta软件工程师Mergen Nachin 详细介绍了新的ExecuTorch技术的全部内容及其重要性。

他指出,当今的人工智能模型正在从服务器扩展到边缘设备,例如移动、AR、VR和AR耳机、可穿戴设备、嵌入式系统和微控制器。
ExecuTorch通过提供PyTorch模型的端到端工作流程来交付优化的本机程序,解决了受限边缘设备的挑战。
Nachin解释说,ExecuTorch从标准PyTorch模块开始,但将其转换为exporter graph,然后通过进一步转换和编译来优化它以针对特定设备。
ExecuTorch的一个主要优势是可移植性,能够在移动和嵌入式设备上运行。
Nachin指出,ExecuTorch还可以通过跨不同目标使用一致的API和软件开发套件来帮助提高开发人员的工作效率。

Nachin表示,随着该技术现已作为PyTorch基金会的一部分开源,我们的目标是帮助行业协作解决将人工智能模型部署到各种边缘设备时的碎片化问题。
Meta相信ExecuTorch可以通过其优化且可移植的工作流程帮助更多组织利用设备上的人工智能。
在PyTorch大会的主题演讲中,Meta软件工程师Mergen Nachin详细介绍了新的ExecuTorch技术的全部内容及其重要性。
作为开源的PyTorch项目的一部分,ExecuTorch的目标是进一步推动这项技术,让世界迎来在移动设备上进行AI推理的新时代。
NumPy代码编译为C /CUDA,提速35倍!
Quansight工程师在PyTorch2.1中通过torch.compile实现了对NumPy代码跟踪的支持。
此功能利用PyTorch的编译器生成高效的融合矢量化代码,而无需修改原始NumPy代码。
它还允许通过torch.device("cuda")下的torch.compile运行来在CUDA上执行 NumPy代码。
那么,这项更新具体有多高效呢?在X(Twitter)上业界大佬Sebastian进行了测试:
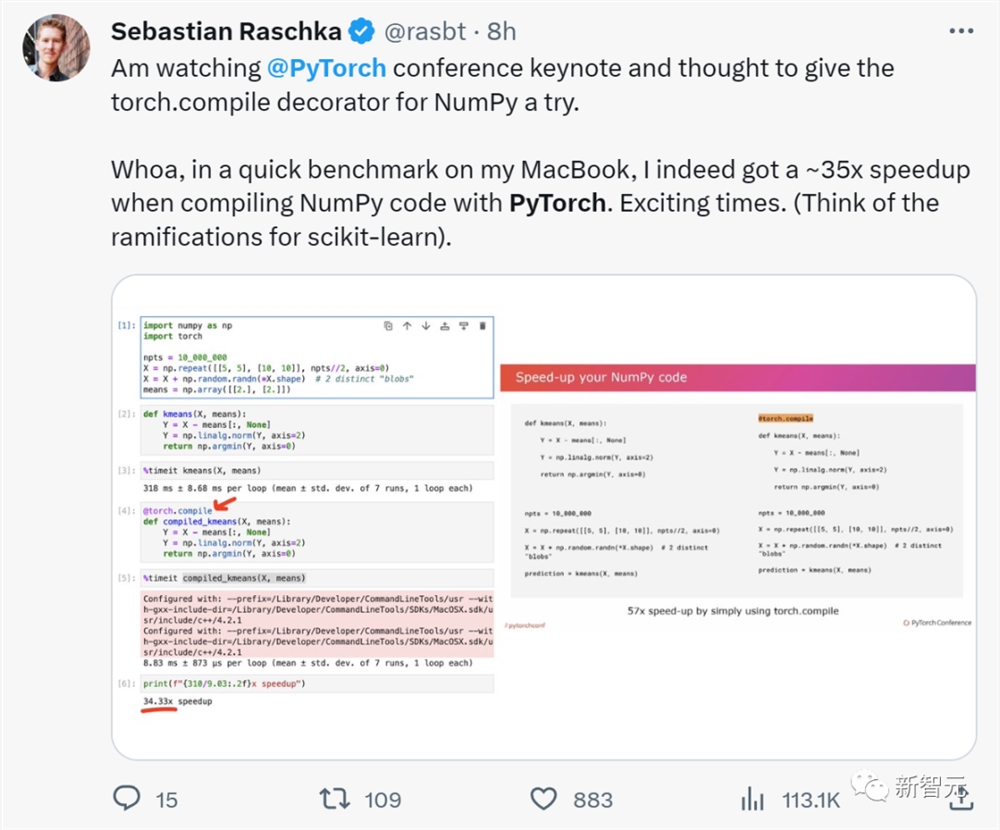
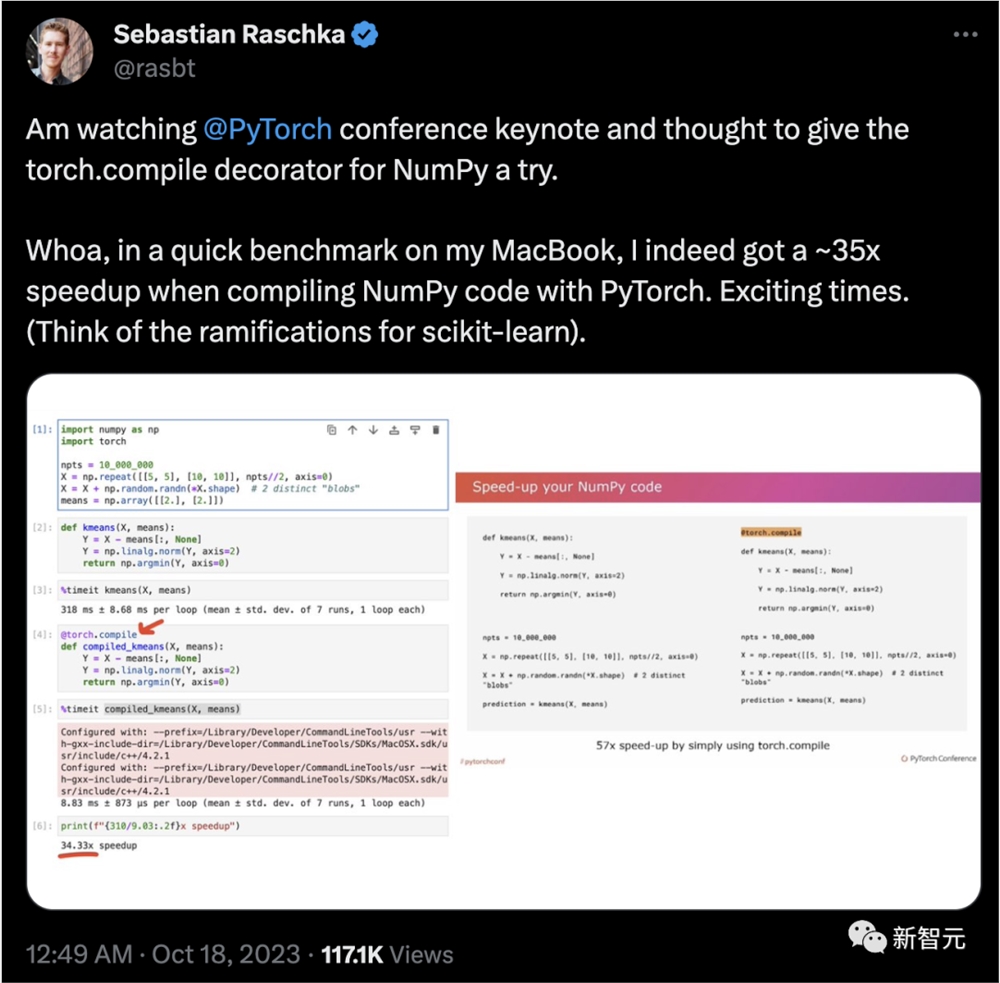
他在观看Pytorch会议主题演讲之后,尝试了一下NumPy的torch.compile。
在MacBook上使用PyTorch编译NumPy代码时都能获得了大约35倍的加速,更别提对scikit-learn的影响了!
网友Anirudh Tulasi感叹道:哇,这些基准测试结果令人印象深刻!torch.compile在MacBook上如此显著地提高NumPy代码性能,真是令人震惊。这对scikit-learn等库的影响可能是革命性的。渴望看到更多的应用!
还有Ph.D说绝对需要尝试这个功能更新。

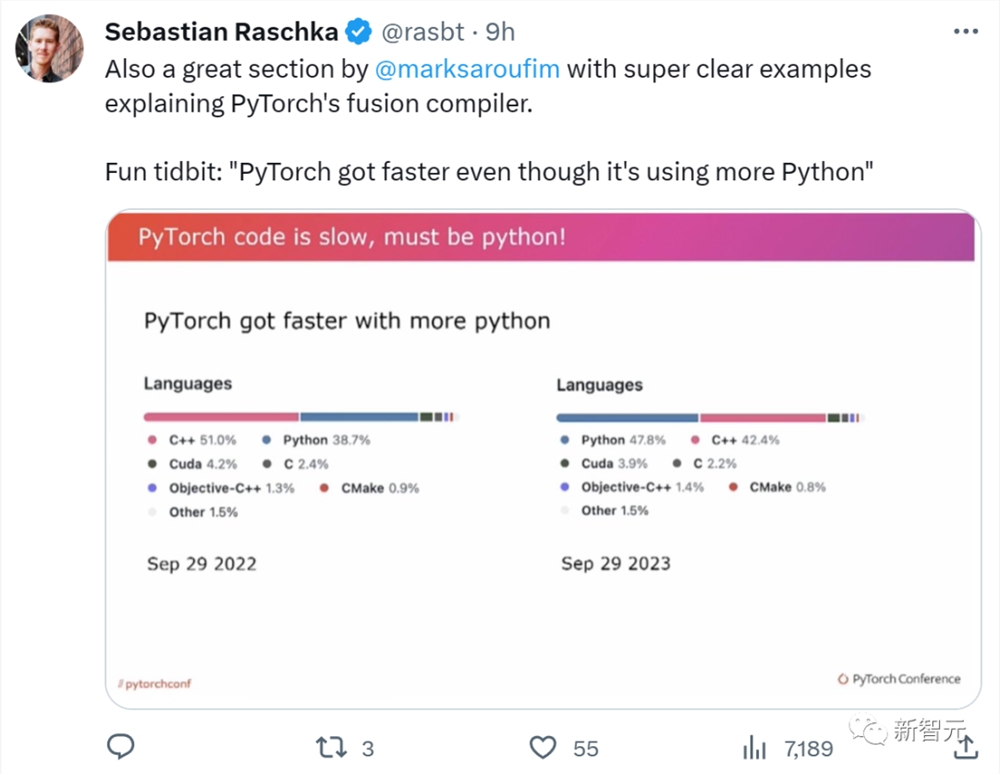
不过,在Pytorch发布会上,Sabastian还发现了一个小花絮,在新版本的Pytorch2.1其Python占比高达47.8%,比去年版本高了9.1%。
我们知道Python代码的执行效率是比C 要低很多的,然而新版本的执行速度比以前快好几倍。
一些网友表示不可思议,不敢相信自己的眼睛。
PyTorch2.1发布
本月初,官方发布了PyTorch2.1。
PyTorch2.1在torch.compile、torch.distributed.checkpoint中提供自动动态形状支持,用于在多个队列上并行保存/加载分布式训练作业,以及 torch.compile对NumPy API的支持。
此外,此版本还提供了许多性能改进(例如CPU电感器改进、AVX512支持、缩放点积注意力支持)以及torch.export的原型版本、健全的全图捕获机制和 torch.export基于量化。
除了2.1之外,官方还发布PyTorc域库的一系列测试版更新,包括TorchAudio和TorchVision。下面是最新稳定版本和更新的列表。

地址:https://pytorch.org/blog/new-library-updates/
- 0000
- 0001

 0000
0000- 0000
- 0000


