斯坦福博士推加速推理新方法Flash-Decoding 长上下文LLM推理速度提8倍
要点:
1. FlashAttention团队推出了一种新的方法,Flash-Decoding,用于加速大型Transformer架构的推理,最高可提速8倍,特别适用于长上下文LLM模型。
2. Flash-Decoding的优点在于使用并行操作加载Key和Value缓存,然后重新缩放和合并结果,以显著提高推理速度。
3. 这个方法在CodeLLaMa-34b上进行了基准测试,结果显示Flash-Decoding可以将长序列解码速度提高8倍,同时具有更好的扩展性。
FlashAttention团队最近推出了一项名为Flash-Decoding的新方法,旨在加速大型Transformer架构的推理过程,特别是在处理长上下文LLM模型时。这项方法已经通过了64k长度的CodeLlama-34B的验证,而且得到了PyTorch官方的认可。
Flash-Decoding的核心思想是通过并行操作来加载Key和Value缓存,然后重新缩放并合并结果,从而实现大幅的推理速度提升。这个方法克服了在处理大型模型时注意力计算带来的性能瓶颈。
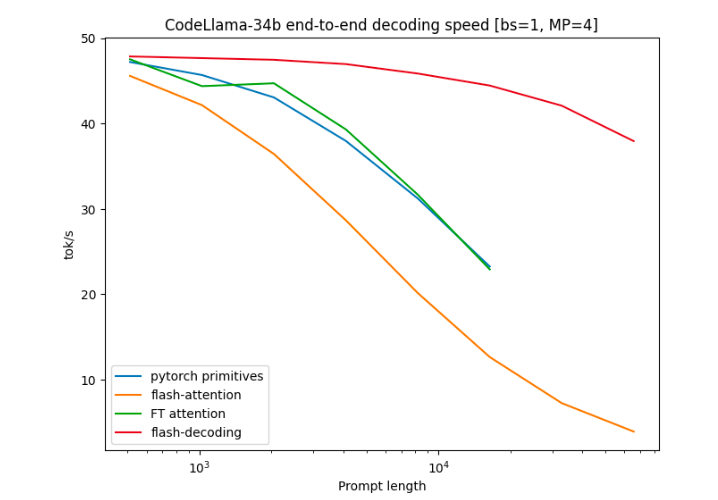
在基准测试中,作者将Flash-Decoding与其他注意力计算方法进行了比较,包括PyTorch原语运行的注意力、FlashAttention v2以及FasterTransformer的注意力内核。结果显示,Flash-Decoding可以将长序列解码速度提高8倍,并且在处理不同序列长度和批处理大小时表现出更好的扩展性。
这一方法的出现为大型Transformer模型的推理过程提供了更高效的解决方案,特别是在处理长上下文模型时,将大幅提高推理速度,有望在未来的大型自然语言处理任务中发挥重要作用。Flash-Decoding的实际使用方法也相对简单,可以根据问题的大小自动选择使用Flash-Decoding或FlashAttention方法。
作者团队中的Tri Dao是FlashAttention的主要作者,他已经加入大模型创业公司Together AI,并将担任普林斯顿大学的助理教授。这个新方法的推出为深度学习领域带来了更多的创新和性能提升。
参考资料:https://princeton-nlp.github.io/flash-decoding/
- 0004
 0001
0001- 0002
- 0000
- 0000