Mini- DALLE 3:提高大模型的文本到图像生成技术
站长网2023-10-18 11:43:050阅
要点:
1. 近两年内,文本到图像(T2I)模型发展迅猛,产生了高质量、多样性和创造性的图像生成,但大多数模型难以与自然语言有效沟通,需要复杂的提示调整。
2. 研究人员受到DALLE3的启发,提出了交互式文本到图像(iT2I)任务,使人们能够与大型语言模型(LLM)进行自然语言交互,实现高质量图像生成和问题回答。
3. 他们提出了一种简单方法,通过提示技巧和现成的T2I模型扩展LLM,以实现iT2I,而不需要额外的训练。他们展示这种方法对LLM的固有功能,如问题回答和代码生成,影响较小。
近年来,文本到图像(T2I)模型的快速发展为人工内容生成带来了革命性的变化,这些模型在不到两年的时间内就能够生成高质量、多样性和创造性的图像。然而,大多数现有的T2I模型存在一个问题,它们难以有效地与自然语言进行交流,通常需要复杂的提示调整和特定的词语组合。
https://minidalle3.github.io/
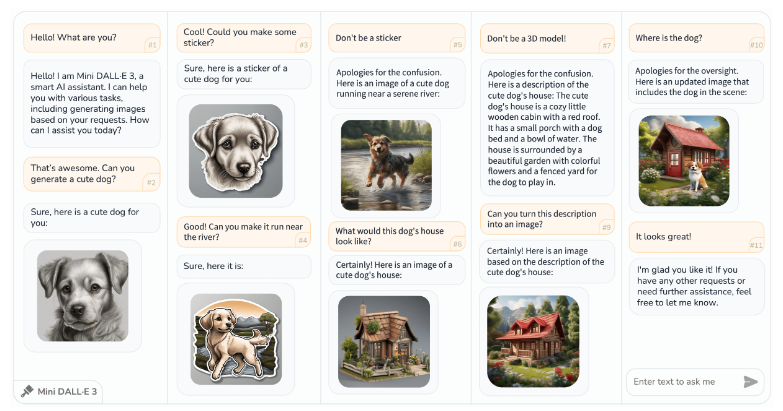
受到DALLE3的启发,研究人员提出了一种新的任务,即交互式文本到图像(iT2I),使人们能够与大型语言模型(LLM)进行自然语言交互,实现高质量图像生成和问题回答。他们还提出了一种简单的方法,通过提示技巧和现成的T2I模型,来扩展LLM以实现iT2I,而不需要额外的训练。
研究人员在不同的LLM下,如ChatGPT、LLAMA、Baichuan等,对他们的方法进行了评估,展示了这种方法可以方便且低成本地为任何现有的LLM和文本到图像模型引入iT2I功能,同时对LLM的固有功能,如问题回答和代码生成,影响较小。
这项工作有望引起广泛关注,为提高人机交互体验以及下一代T2I模型的图像质量提供启发。文章的研究对于促进人机交互和改进图像生成质量具有潜在的重要意义。
0000
评论列表
共(0)条相关推荐
- 0001
- 0000
- 0000
- 0000
- 0000