香港中文大学发布全面中文大语言模型评测CLEVA
核心要点:
香港中文大学的研究团队发布了全面的中文大语言模型评测方法,已被EMNLP2023System Demonstrations录取。
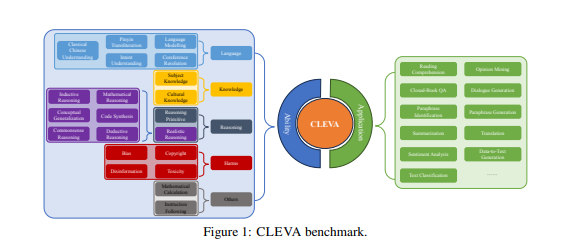
该评测方法包含31个任务和多种评测指标,覆盖了84个数据集,着重关注准确性、鲁棒性、公平性等多个维度。
评测方法还提供多样的提示模版,降低数据污染风险,以及提供清晰的操作界面,可供研究团队使用和交互评测。
香港中文大学的研究团队最近发布了一项全面的中文大语言模型评测方法,这一方法已经被EMNLP2023System Demonstrations录取。这一评测方法名为CLEVA,是由香港中文大学计算机科学与工程学系的王历伟助理教授领导的研究团队开发的,与上海人工智能实验室合作研究。
CLEVA的目标是为中文大语言模型提供全面的评测,覆盖多个任务和多个评测指标,以更好地理解和评价这些模型的能力。
论文地址:https://arxiv.org/pdf/2308.04813.pdf
这一评测方法包含了31个任务,其中包括11个应用评估和20个能力评测任务,共涵盖了来自84个数据集的370,000多个中文测试样本。这是过去同类工作中样本数量最多的,为全面评测提供了更多的数据支持。
CLEVA不仅关注传统的准确性指标,还引入了鲁棒性、公平性、效率、校准与不确定性、偏见与刻板印象以及毒性等多维度的评测指标,以更全面地评价大语言模型的性能。
为了确保评测的可比性,CLEVA为每个评测任务准备了一组多个提示模板,使所有模型都使用相同的提示模板进行评测。这有助于公平比较模型能力,同时还可以分析模型对不同提示模板的敏感程度,为模型的下游应用提供指导。
此外,CLEVA还采取了多种方法来降低数据污染的风险,包括采用新数据和不断更新的测试集。
这一全面的中文大语言模型评测方法旨在提供更可信的评测结果,为学术界和工业界提供更准确的模型能力认知。研究团队已经使用CLEVA评测了23个中文大模型,并计划持续评测更多的模型。其他研究团队也可以通过CLEVA网站提交和对接评测结果,从而促进大模型能力的认知和评测。
- 0000
- 0003
 0000
0000- 0000

 0000
0000