ReCon框架帮助AI大模型识破谎言 增加AI智能体的安全性
要点:
1. ReCon框架通过引入「三思而后行」和「换位思考」的思维过程,提高大语言模型在欺骗性环境中的决策能力,增加AI智能体的安全性与可靠性。
2. 清华大学与通用人工智能研究院的研究团队以阿瓦隆桌游为例,测试了大语言模型在充满欺骗的环境下的局限性,提出ReCon框架来解决这些问题。
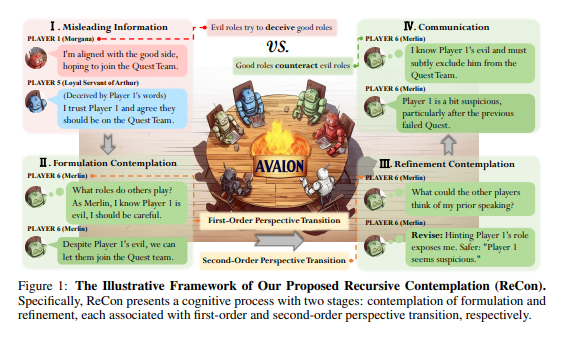
3. ReCon框架主要包含两个阶段的思考过程,即「构思思考」和「改进思考」,通过一阶视角转换和二阶视角转换,提高大语言模型识别和应对欺骗的能力。
随着大语言模型的不断进展,AI智能体的发展也变得更加蓬勃。然而,研究者发现在未来无人监管的情况下,防止AI智能体被欺骗和误导是一个被忽视的问题,因为人类社会中存在着大量误导和欺骗性的信息,如果AI智能体不能有效地识别和应对这些信息,可能会导致不可估量的后果。
论文地址:https://arxiv.org/pdf/2310.01320.pdf
为了解决这个问题,一支由清华大学与通用人工智能研究院的研究团队组成的研究团队以阿瓦隆桌游为例,测试了大语言模型在充满欺骗的环境下的局限性,并提出了ReCon框架。
ReCon框架受到人类思考中的「三思而后行」和「换位思考」的启发,通过引入两个主要的构思阶段,即「构思思考」和「改进思考」,并综合了一阶视角转换和二阶视角转换的思考方式,来提高大语言模型对欺骗的识别和应对能力。
该研究发现大语言模型在欺骗性环境中面临三大挑战:恶意信息的误导、私有信息泄露以及内部思考的不透明性。ReCon框架通过重新思考大语言模型在欺骗性环境中的策略,帮助解决了这些挑战。
在ReCon框架中,构思思考阶段旨在生成模型的初始思考和发言内容,而改进思考阶段旨在对这些内容进行更为精细的优化和调整。
通过这一研究,研究团队发现ReCon框架能够在无需微调和额外数据的情况下显著提高大语言模型的识别和应对欺骗的能力。
此外,研究还提出了现有大语言模型在安全、推理、说话方式和格式等方面的不足,并为后续研究指明了可能的方向。这一研究对于提高AI智能体的安全性和可靠性具有重要意义。
- 0000
- 0000
- 0000
- 0000
- 0000