FAVOR:通过精细融合音频和视觉细节提升大模型视频理解能力
站长网2023-10-12 11:54:430阅
研究人员日前发布了一项名为"FAVOR"的创新技术,它能够在帧级别巧妙地融合音频和视觉细节,从而增强大型语言模型对视频内容的理解能力。
这一引入FAVOR方法的举措,为拓展大型语言模型在视频理解领域的潜力开辟了新的机遇。这一创新技术通过精细融合音频和视觉信息,显著提高了视频理解的准确性和效率,有望对人工智能视频理解技术的进步产生积极的影响。
项目地址:https://github.com/the-anonymous-bs/FAVOR
核心功能:
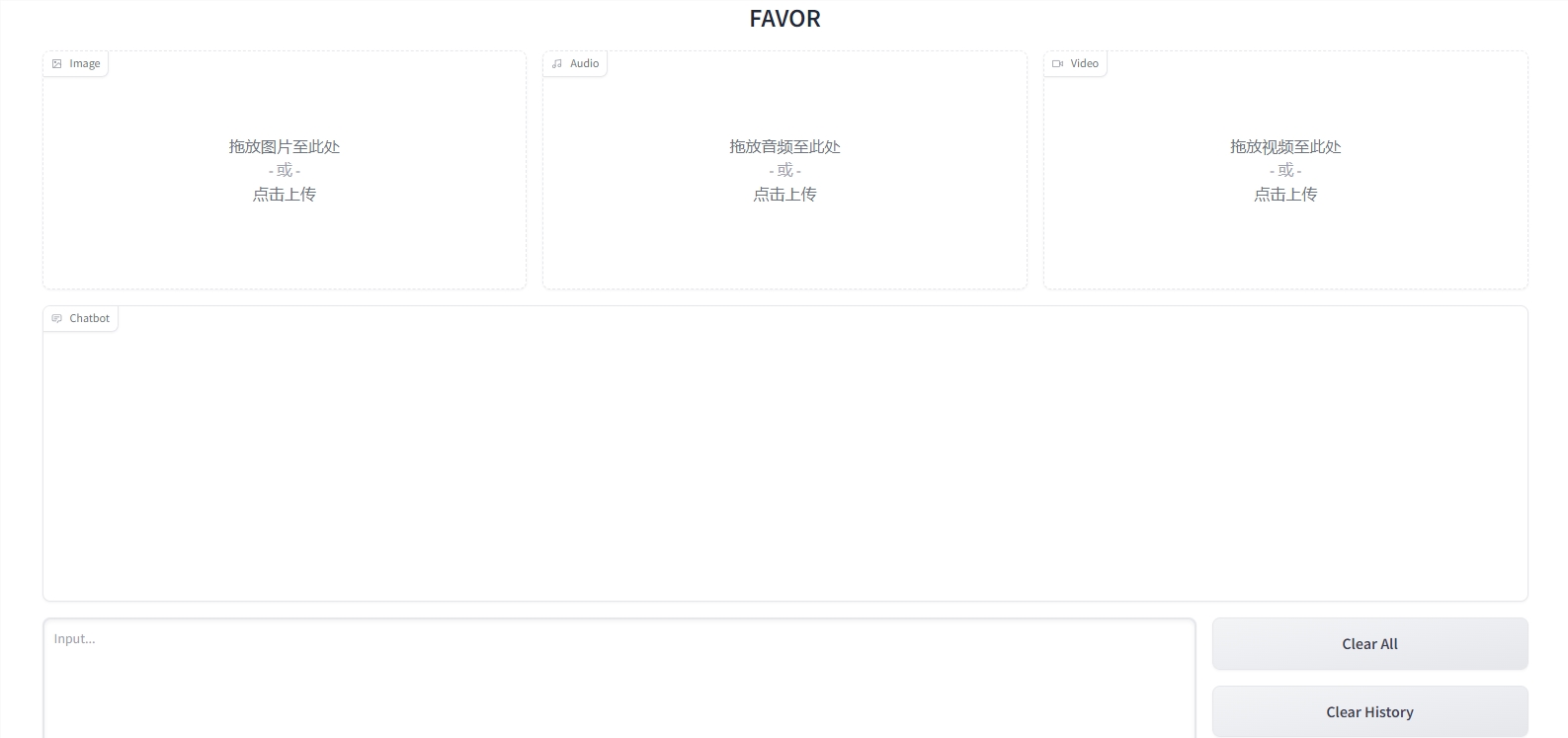
多模态支持: FAVOR支持多种输入模态,包括文本、图像、音频和视频。用户可以轻松结合这些不同的媒体类型,以更精确地表达他们的需求。
清除历史记录: FAVOR允许用户清除聊天历史,以确保他们的会话始终保持整洁。这有助于更好地组织对话,同时保留所有输入模态。
提交和重新提交: 用户可以通过点击"Submit"按钮来发送他们的请求,获取模型的响应。如果需要重新发送相同请求,可以使用"Resubmit"选项,同时清除上一轮的对话。
参数控制: FAVOR提供了控制生成文本的参数,包括最大长度、Top-P和温度。这使用户能够微调生成的文本,以满足他们的需求。
提供示例: 项目提供了论文中提到的示例,以帮助用户更好地了解如何使用FAVOR。这些示例可以作为起点,帮助用户开始构建他们自己的多模态交互。
0000
评论列表
共(0)条相关推荐
- 0000
- 0000
- 0000

 0007
0007- 0000