清华芯片新突破登Science,获评“存算一体领域重大进展”!基于类脑架构实现片上快速AI学习
清华最新芯片成果,登上Science!
全球首颗全系统集成、支持高效片上学习的忆阻器存算一体芯片,正式问世。
它集合了记忆、计算和学习能力。
能在片上快速完成不同任务的模型训练。
而能耗仅为先进工艺下ASIC的1/35,能效有望提升75倍,同时兼顾保护隐私。
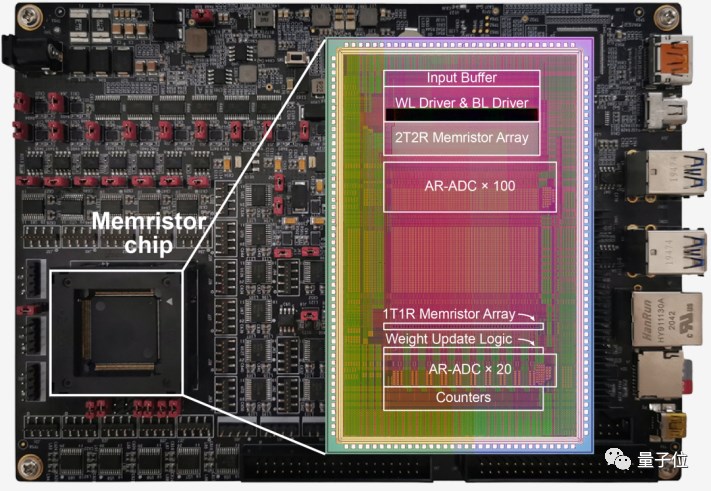
这就是由清华大学集成电路学院吴华强教授、高滨副教授团队带来的最新成果。
相关话题已经登顶知乎热榜。

Science编辑评价其为:
存算一体领域的重要进展。
芯片内搞定AI训练
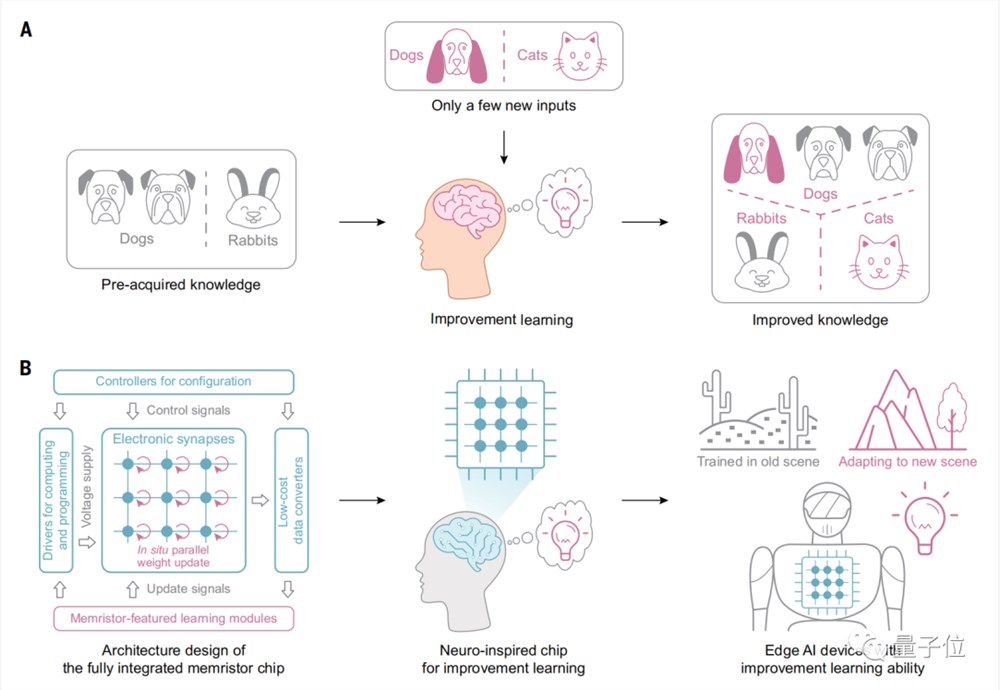
正如人类大脑能够基于预先接受过的知识,快速学习新场景中的新知识。
边缘设备也需要具备类似的学习能力,才能更好适应用户习惯和新场景。
但是目前神经网络训练需要将大量数据在计算和存储单元之间来回移动。这使得在边缘设备上很难高效进行训练任务。
基于忆阻器内存高速访问、断电后仍可保存数据的特性,可以实现内存 硬盘二合一,解决数据的大量移动,从而进一步实现了完全在芯片上进行学习任务。
由此,清华团队提出忆阻器存算一体芯片。
它集成了高性能忆阻器阵列和必备模块,同时也是一块类脑计算芯片(neuro-inspired computing chip)。
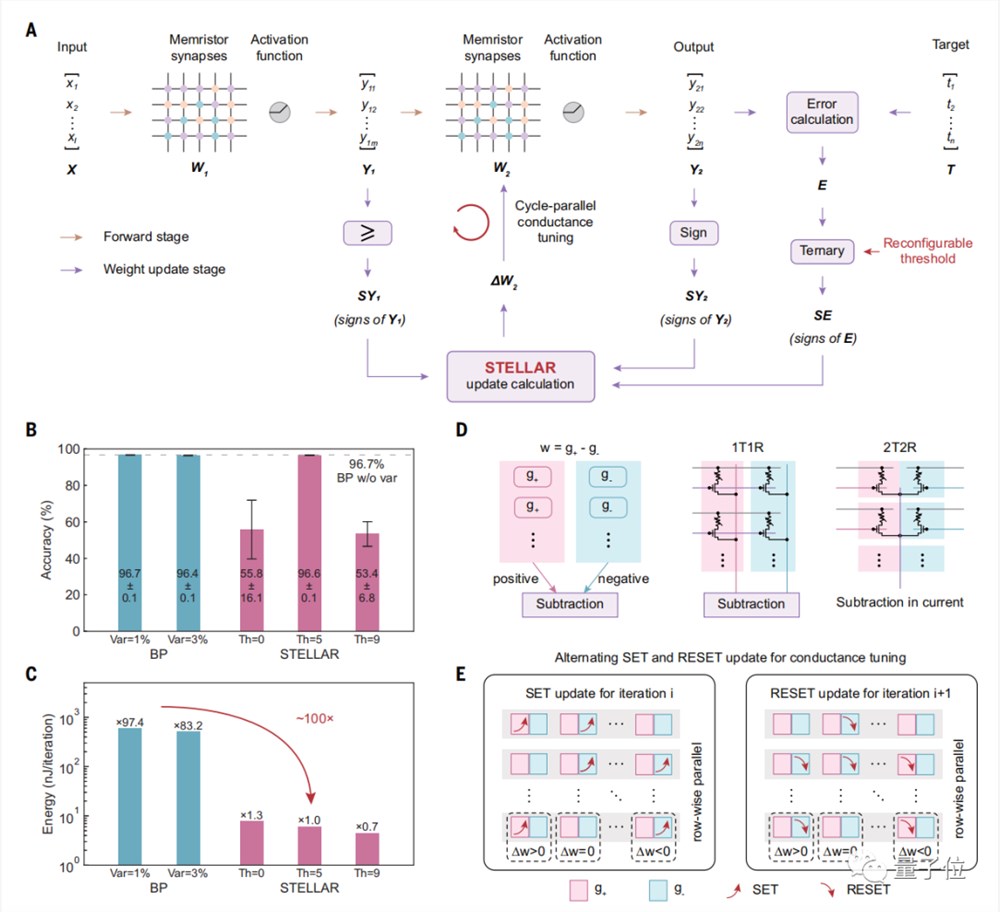
为此,研究团队提出了一种新型通用算法和架构(STELLAR)。
它利用忆阻器的特性,通过仅计算正负号、预定义阈值、循环调谐等设计,提升正向传播算法映射到芯片硬件上的效率,从而实现了高效率、低功耗的片上学习。
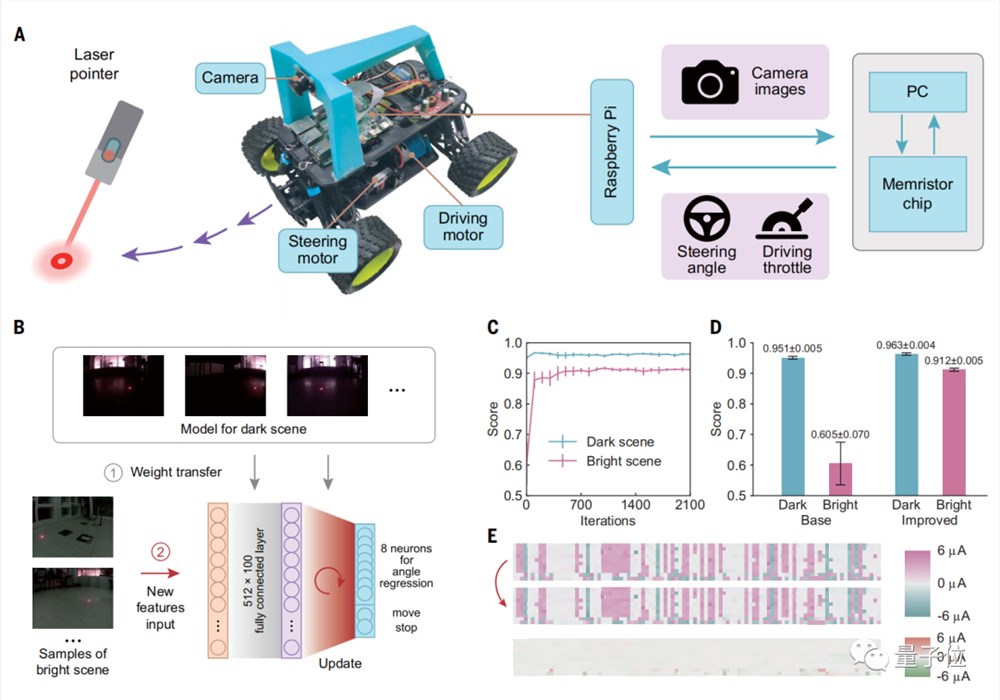
研究人员通过几个实验来验证片上学习的能力。
第一个实验中,有一台追踪光点的小车。在进行提升学习前,小车在明亮场景中会跟丢光点。
而通过500个训练样本进行端侧学习后,小车在明亮和黑暗场景中都能很好完成任务。
从下图D中可以看到,小车在明亮场景下的得分从原来的0.602提升到了0.912。
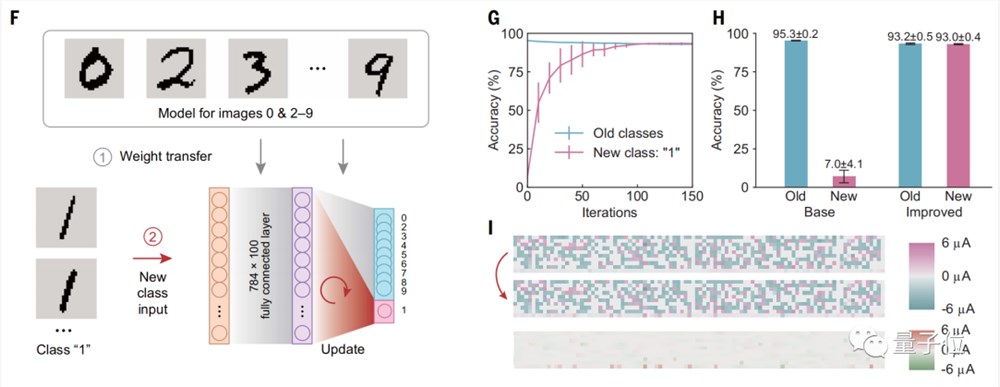
另一个实验是进行图像识别。
实验步骤是先让基本模型识别数字“0”和“2-9”,然后让模型学习识别数字一个新类别的“1”。
结果可以看到,在经过150次训练后,进行提升学习能将准确度从7%提升到93%。
研究团队十余年攻坚
本次成果来自清华大学集成电路学院吴华强教授、高滨副教授团队。
吴华强教授现任清华大学集成电路学院院长、清华大学微纳加工中心主任。
2005年在美国康奈尔大学(Cornell University)电子与计算机工程学院获工学博士学位。随后先后在美国Spansion公司和美国Primet Precision Materials公司分别担任高级工程师和技术主管。
2009年,加入清华大学微电子学研究所。
研究方向为新型存储器及基于忆阻器的存算一体,涵盖从器件、工艺集成、架构、算法、芯片以及系统等多个层次。
高滨副教授于2013年获得北京大学微电子与固体电子学专业力学博士学位,2015年加入清华大学微纳电子系。
研究方向为新型存储器,器件模型与模拟,设计-工艺协同优化,存算一体与神经形态芯片,信息安全芯片。
张文彬、姚鹏作为学术论文的第一作者。
实际上,关于该方向的存算一体芯片,清华团队已经探索了十余年。
2012年,钱鹤、吴华强团队开始研究用忆阻器来做存储。研究团队最初在实验室中探索忆阻器器件的一致性和良率。
2014年,清华大学与中科院微电子所、北京大学等单位合作,优化忆阻器的器件工艺,制备出高性能忆阻器阵列——这一次提出的最新成果中已应用。
2020年,钱鹤、吴华强团队基于多阵列忆阻器,搭建了一个全硬件构成的完整存算一体系统,在这个系统上高效运行了卷积神经网络算法,成功验证了图像识别功能,比图形处理器芯片的能效高两个数量级,大幅提升了计算设备的算力,实现了以更小的功耗和更低的硬件成本完成复杂的计算。
如今,随着大模型趋势到来,AI算力瓶颈问题更加突出,存算一体等新方案也备受关注。
Science编辑表示,基于忆阻器的芯片技术近期受到非常大的关注,它有望克服冯诺依曼架构造成的算力瓶颈。
论文地址:
https://www.science.org/doi/abs/10.1126/science.ade3483
- 0000
- 0000
- 0000
- 0000
- 0000

