谷歌、CMU研究表明:语言模型通过使用良好的视觉tokenizer首次击败了扩散模型
站长网2023-10-11 17:56:520阅
要点:
1. 研究表明,在图像和视频生成领域,语言模型通过使用良好的视觉 tokenizer 首次击败了扩散模型,强调了 tokenizer 的重要性。
2. 传统大型语言模型(LLM)在图像生成方面一直落后于扩散模型,主要原因是缺乏有效的视觉表示。
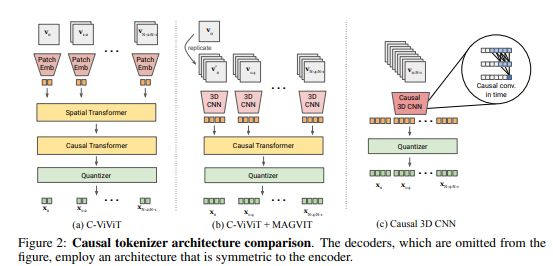
3. 新研究引入了名为MAGVIT-v2的视频 tokenizer,采用无查找量化和增强功能的设计,取得了在图像和视频生成、视频压缩以及动作识别领域的显著性能提升。
来自谷歌、CMU 的研究发现,语言模型在图像、视频生成领域的性能一直不如扩散模型,主要原因是缺乏有效的视觉表示。
然而,通过引入一种名为MAGVIT-v2的视频 tokenizer,采用无查找量化和增强功能的设计,研究者成功改进了图像和视频生成的质量,超越了现有技术。
论文地址:https://arxiv.org/pdf/2310.05737.pdf
实验证实,良好的视觉 tokenizer 在使语言模型生成高质量图像和视频方面具有关键作用。
这一研究的重要性在于它为语言模型的多模态应用提供了新的思路,通过将视觉和语言统一在相同的 token 空间中,可以提高多模态语言模型的性能,加快视频应用的处理速度,并提高视频压缩质量。
此外,新的 token 也提供了更好的视觉理解,增强了模型的鲁棒性和泛化性。通过这一研究,我们可以看到语言模型在视觉生成领域的潜力,以及如何通过创新的设计和改进来实现更好的性能。
0000
评论列表
共(0)条相关推荐
 0000
0000- 0000
- 0000
- 0000
- 0000



