DistilBERT:更小、更快、更便宜的大型语言模型压缩方法
站长网2023-10-08 09:56:450阅
要点:
1. 近年来,大型语言模型的发展迅猛,BERT成为其中最受欢迎和高效的模型,但其复杂性和可扩展性成为问题。
2. 为了解决这个问题,采用了知识蒸馏、量化和修剪等压缩算法,其中知识蒸馏是主要的方法,通过让较小的模型模仿较大模型的行为来实现模型压缩。
3. DistilBERT是从BERT中学习并通过包括掩码语言建模损失、蒸馏损失和相似性损失在内的三个组件更新权重,它比BERT小、快、便宜,但性能仍然相当。
近年来,大型语言模型的发展迅猛,BERT成为其中最受欢迎和高效的模型,但其复杂性和可扩展性成为问题。为了解决这些问题,市面上目前由三种常见的模型压缩技术:知识蒸馏、量化和剪枝。
知识蒸馏的目标是创建一个较小的模型,可以模仿较大模型的行为。为了实现这一目标,需要一个已经预训练好的大型模型(如BERT),然后选择一个较小模型的架构,并使用一个适当的损失函数来帮助较小模型学习。这里大模型被称为“教师”,较小模型被称为“学生”。知识蒸馏通常在预训练过程中应用,但也可以在微调过程中应用。
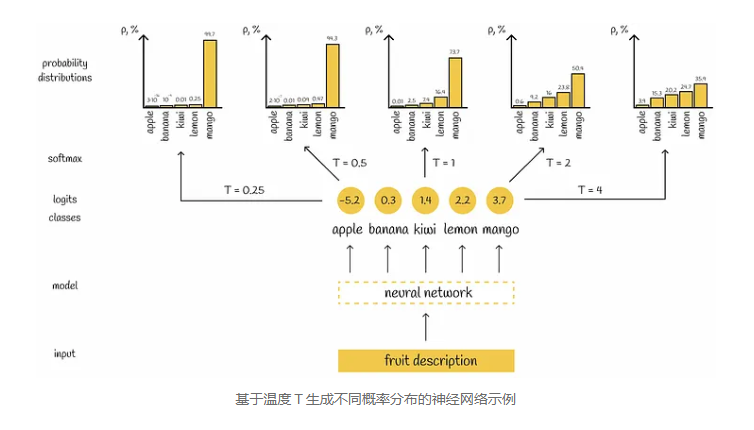
DistilBERT从BERT学习,并通过包括掩码语言建模(MLM)损失、蒸馏损失和相似性损失在内的三个组件的损失函数来更新其权重。文章解释了这些损失组件的必要性,并引入了softmax温度的概念,用于在DistilBERT损失函数中平衡概率分布。
DistilBERT的体系结构,包括与BERT相似但有一些差异的地方,以及在性能优化方面采用的一些最佳实践。最后,文章总结了BERT和DistilBERT在性能和规模方面的比较,指出DistilBERT在保持可比性能的同时,更小更快。
总之,DistilBERT通过知识蒸馏技术在保持性能的同时显著压缩了大型语言模型,为在资源受限设备上的部署提供了可能性。
0000
评论列表
共(0)条相关推荐
 0001
0001- 0000
- 0000
- 0000
- 0000

