码农狂喜!微软提出CodePlan,跨168个代码库编码任务,LLM自动化完成
这一次,微软提出的CodePlan让码农的生产力又提高了!
对于大模型来说,擅长的是本地化编码任务。
但如果任务跨越了多个相互依赖的文件,LLM却无法解决。

对此,微软研究人员设计了一个任务无关的神经网络框架,名为CodePlan。
论文地址:https://arxiv.org/pdf/2309.12499.pdf
论文中,CodePlan综合了多步骤编辑链(chain-of-edits),是一种将程序分析、规划和LLM结合在一起的新方法。
一起来具体看看,CodePlan是如何设计的?
CodePlan:大模型 规划
软件工程活动中,例如软件包迁移、修复静态分析或测试的错误报告,以及向代码库添加类型提示或其他规范,涉及到对整个代码存储库的普遍编辑。
研究人员将这些活动规划,为「存储库级别的编码任务」。
随着编码工具如GitHub Copilot、Code Whisperer得到了大模型能力加持,已经为码农在本地化编码问题提供了解决方案。
然而,现实是,「存储库级别的编码任务」更加复杂,不能直接通过LLM解决,因为存储库中的代码是相互依赖的,整个存储库可能太大而无法纳入提示。
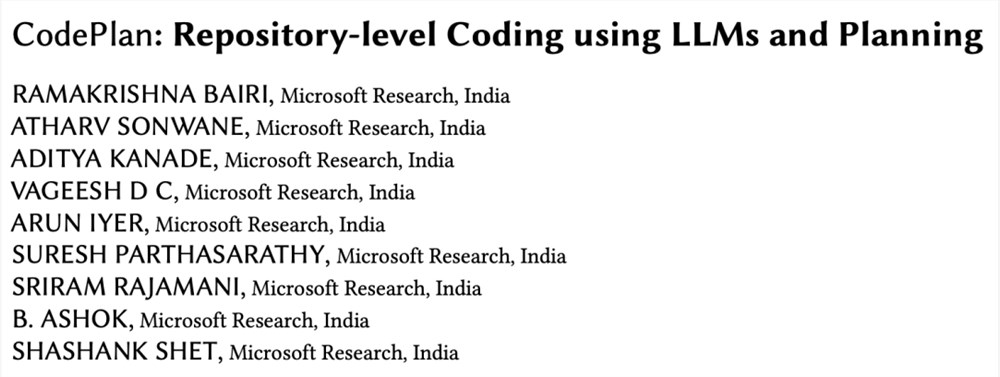
这项研究中,微软团队将库级编码框架作为一个规划问题,并提出了一个任务不可知的框架,称为CodePlan。
CodePlan综合了一个多步骤的编辑链(计划) ,其中每一步都会调用代码位置上的LLM。该代码位置上的上下文来自整个存储库、以前的代码更改和特定于任务的指令。
CodePlan是基于增量依赖分析、变更可能影响分析和自适应规划算法的新型组合。
如下图,展示了复数库API的变化,微软研究人员的任务是根据这一变化迁移代码库。

图3左侧显示了代码库中使用复数库的相关部分。
具体来说,Create.cs文件中的方法func,调用了库中的create_complex方法,Process.cs文件中的方法Process.cs调用了func。

研究人员将图1中的任务描述和func主体传递给LLM,以生成修改后的func代码,如图3右侧所示。
可以看到,LLM已经正确地编辑了对create_complex API的调用,以便它返回一个Complex类型的对象,而不是两个浮点值的元组。
注意,这个编辑导致了方法func的签名发生了变化——它现在返回了一个Complex类型的对象。
这就需要修改方法func的调用者,比如Process.cs中的process方法,如图3左下角所示。如果不对process方法的主体进行适当的修改,代码就不能构建!
图3右下方显示了对process方法的适当修改,它能使版本库达到一致的状态,从而在编译时不会出错。
对于研究人员来说,最主要的是构建一个「存储库级别的编码系统」,能自动生成编辑所需的派生规范。
LLM驱动的库级编码任务定义如下:

CodePlan整体框架中,输入是一个存储库、一个通过自然语言指令或一组初始代码编辑表达种子规范的任务,一个正确性oracle和一个 LLM。
CodePlan构建了一个计划图,图中的每个节点都标识 LLM需要履行的代码编辑义务,而边则表示目标节点需要在源节点之后履行。
CodePlan监控代码编辑,并自适应地扩展计划图。
一旦计划中的所有步骤都已完成,存储库将由oracle进行分析。如果oracle验证了资源库,则任务完成。如果发现错误,错误报告将作为下一轮计划生成和执行的种子规范。

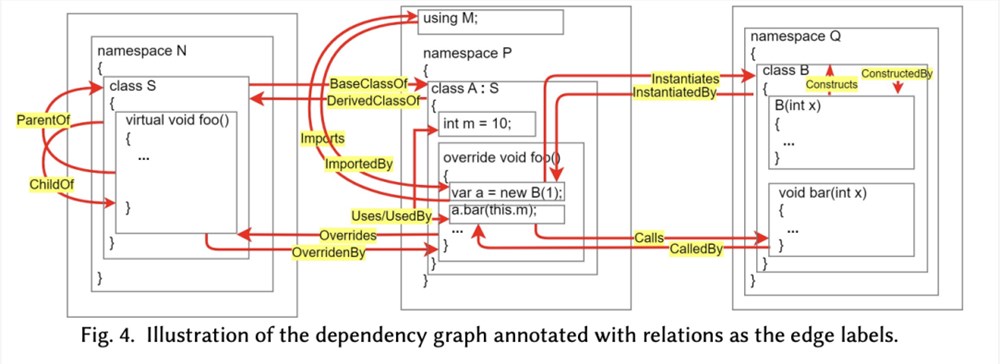
此外,CodePlan算法还维护了一个依赖关系图,图4说明了依赖关系图的结构。
刷新SOTA
研究人员评估了CodePlan在两个存储库级任务上的有效性: 包迁移 (C#)和时态代码编辑(Python)。
每个任务在多个代码库上进行评估,每个代码库都需要对多个文件(2-97个文件)进行相互依赖的更改。

这种复杂程度的编码任务,以前从未使用过LLM自动完成。
研究结果表明,与基线相比,CodePlan更符合基本事实,能够让5/6个存储库通过有效性检查,比如,无差错构建和正确的代码编辑。
总之,CodePlan为自动化复杂的库级编码任务提供了一种有前途的方法,既提高了生产率,又提高了准确性。
它成功应对了许多挑战,为高效可靠的软件工程实践开辟了新的可能性。
参考资料:
https://twitter.com/adityakanade0/status/1706291449674039711
- 0000
- 0000
- 0000


 0000
0000- 0000



