拒绝“白嫖”!Stack Overflow 将矛头直指 ChatGPT 等产品:用了我的数据训练,得先给钱!
打不过就加入!
继去年12月 Stack Overflow称 ChatGPT 生成的答案正确率非常低并决定宣布临时封禁 ChatGPT之后,其开始以另一种身份加入这场 AI 竞赛中。
据外媒Wired 报道,开发运行 ChatGPT 和 DeLL-E 等“病毒式” AI 工具系统可能会使得背后的公司如 OpenAI 花费数十亿美元,而 StackOverflow 正计划让这笔费用变得更高一些,其希望对使用自己平台数据进行训练的 AI 公司收费。
值得注意的是,现如今和 Stack Overflow 有着类似想法的公司也不在少数, 社交媒体 Twitter、新闻社区 Reddit 等也正有此意,在各方「画地为牢」之际,谁将为大模型的训练买单也成为行业内关注的焦点。
大模型背后的大数据从何而来?
众所周知,ChatGPT、GPT-4、Google Bard、Bing Chat、LLaMA 等 AI 模型都需要基于大量数据集进行训练。
然而,数据从何而来,这些模型背后的开发商 OpenAI、Google、Meta 虽然从未正面解释过这一问题,但是据《华盛顿邮报》的一项调查显示,其中大部分是从互联网上抓取的。
为了验证这一点,《华盛顿邮报》分析了 Google 的 C4数据集,其中包含了1500万个网站内容的快照,它也被用来训练 Google T5、Facebook 的 LLaMA 模型。
通过与艾伦人工智能研究所的研究人员合作,最终他们发现此数据集主要来自新闻、娱乐、软件开发、医药和内容创作等多个行业的网站,覆盖收集来自世界各地发布的专利文本的 patents.google.com、维基百科、仅供订阅的数字图书馆(scribd.com)、Medium,以及 Stack Overflow、Reddit 等平台也在其中。
来自这些网站的数据显然对 AI 模型公司而言非常具有价值,他们可以通过互联网成千上万的信息源,根据参数训练他们的大型语言模型(LLM),从而成功进行自然语言处理(NLP)。
Stack Overflow 反向抵制 AI模型
Stack Overflow 作为全球知名的编码论坛,为开发者提供协作与交流的环境,也是程序员讨论编码问题的主要聚集地。当前,市面上很多的 AIGC 都支持辅助编码、能够在理解用户提出的编码问题基础上提供生成式代码、甚至也可以捕捉 Bug 以及 Debug,而大模型之所以拥有这些能力,也有大量相关编码问题与数据集的支撑。
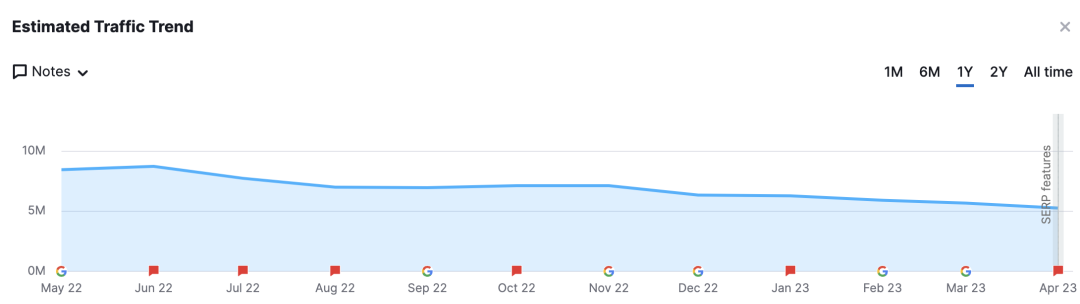
不过,随着 ChatGPT 等产品的到来,对老牌 Stack Overflow 这样的平台带来了巨大的冲击。在今年早些时候,也有媒体报道,Stack Overflow 惨遭程序员抛弃,其网站访问量与搜索量急剧下降。
根据营销平台 Semrush 的流量监测工具显示,近一年来,Stack Overflow 的访问量持续下滑。
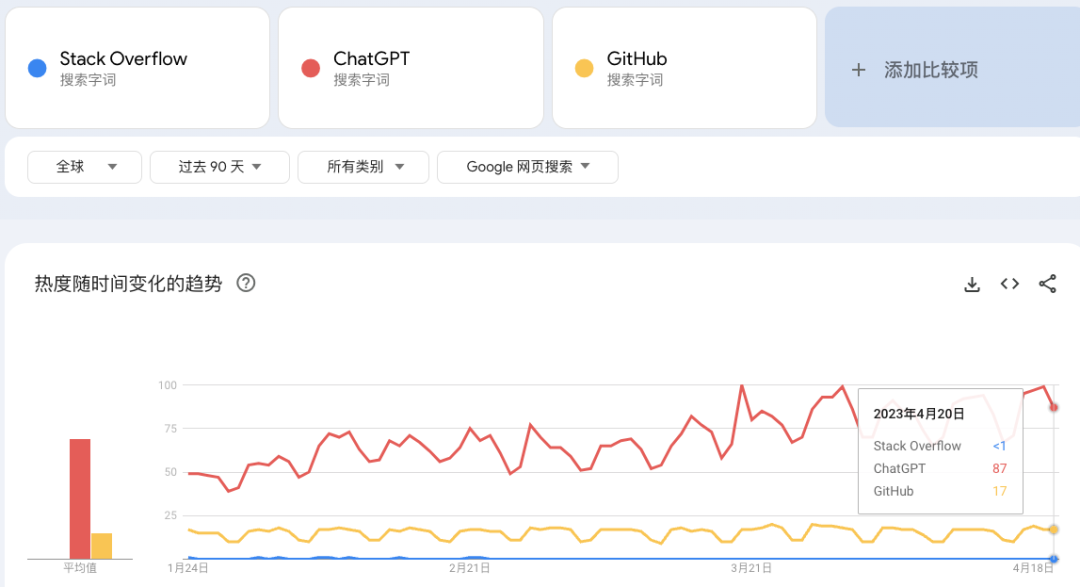
另一方面,以 Stack Overflow、ChatGPT、GitHub 为关键词,据 GoogleTrends 显示,Stack Overflow 的搜索量垫底。
与之形成鲜明对比的是,很多大模型产品已经走向了商业化,如微软对其代码生成器 GitHub Copilot 的收费高达19美元/人/月、OpenAI 推出了每月20美元的 ChatGPT Plus 服务。
在这种趋势之下,Stack Overflow 想要绝地反击,便也不足为奇。据 Wired 报道,StackOverflow CEOPrashanth Chandrasekar 表示,“Stack Overflow 计划最快在今年年中开始向开发大模型的开发者、公司收费,付费的群体才可以获得其服务中的5000万个问题和答案。”
为此,Prashanth Chandrasekar 也在 Stack Overflow 的官方博客上特地发表了一篇主题为《社区是人工智能的未来》的长文,分享道:
如今,建立在尖端大语言模型 (LLM) 之上的复杂聊天机器人只需一张在餐巾纸上画的草图照片即可为网站编写功能代码。他们可以回答有关如何构建应用程序的复杂查询,帮助用户调试错误,并在几分钟内在不同语言和框架之间进行翻译。
在 Stack Overflow,我们不得不坐下来问自己一些尖锐的问题。当用户可以像其他人一样轻松地向聊天机器人寻求帮助时,我们在软件社区中扮演什么角色?我们的业务如何适应,以便我们继续授权技术人员学习、分享和成长?
在Prashanth Chandrasekar看来,「人工智能系统的核心是建立在丰富的人类知识和经验之上。他们通过数据训练来学习——例如开源代码和 Stack Overflow 问答。」
基于此,StackOverflow 想要推出 Stack Overflow for Teams 服务,决定向使用其数据的公司寻求赔偿,这属于维持社区蓬勃发展战略的一部分,无可厚非。
Reddit、Twitter 同样想要对数据收费!
无独有偶,想要强硬地拒绝 AI 模型开发商“白嫖”的平台也不止 Stack Overflow 一家。
就在几天前,美国知名论坛社交平台 Reddit 宣布,它将从6月开始向一些人工智能开发者收取访问其自身内容的费用。Reddit 表示,API 访问收费的细节仍在敲定,价格预计在未来几周内公布。
除此之外,马斯克掌管下的 Twitter 也欲对大模型公司发起反击。在3月26日,Twitter 推出了自家最新的 API 价格结构,包含免费版、基础版以及企业版。
免费版:只有使用 Twitter 登录的访问权限,以及每月仅提供1,500个发帖请求。
基础版:每月100美元,可以获得50,000个发帖请求和10,000个阅读请求。
企业版:并没有列出具体的价格。但是承诺提供“满足您和您客户特定需求的商业级访问”以及“[来自]专门客户团队的托管服务。” 不过,据外媒 Platformer 此前报道,企业版每月的费用可能高达42,000美元。
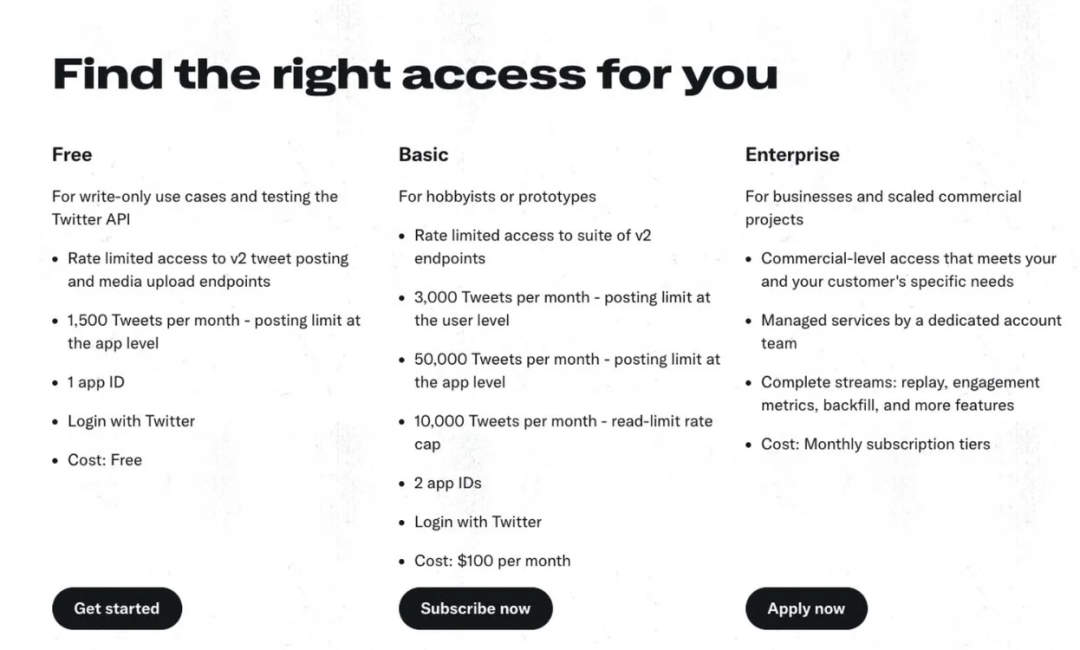
这意味着如果企业想要接入 Twitter API,用上面的数据来训练,需要付出一笔不菲的费用。
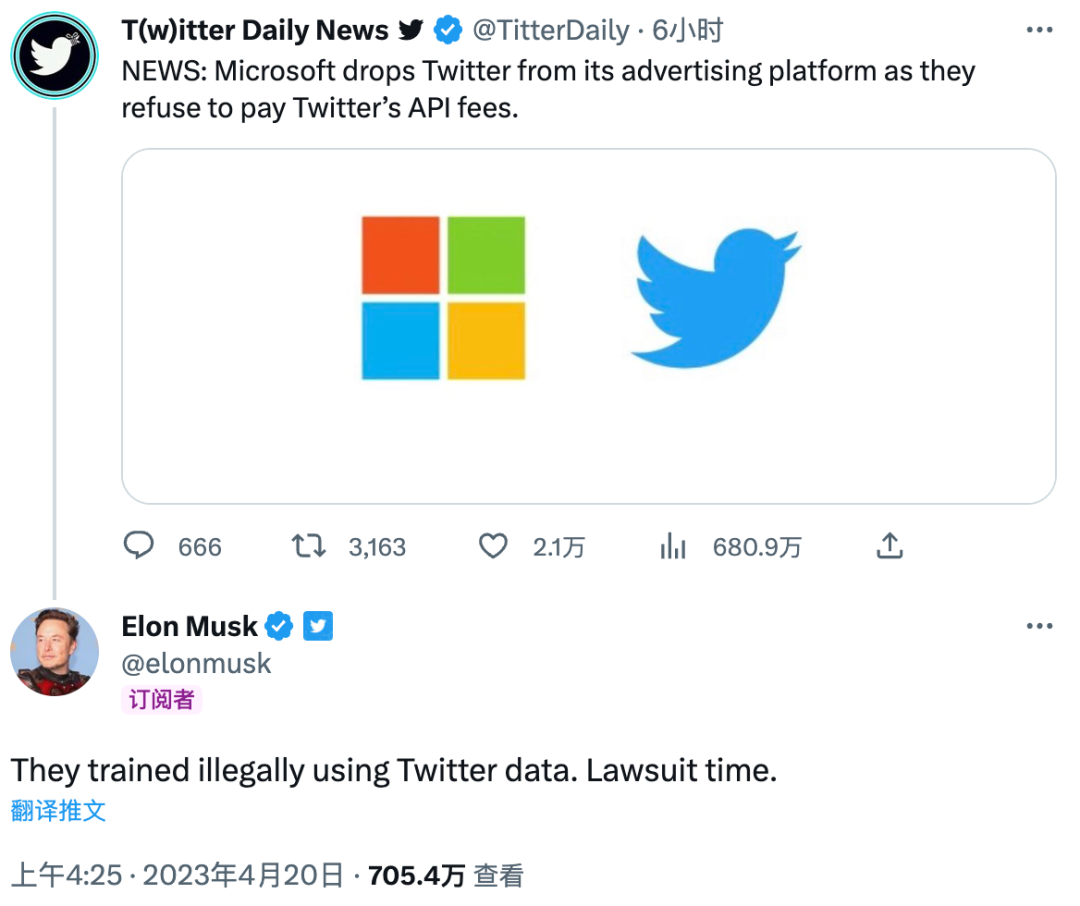
与此同时,马斯克还打算追究旧账,其认为 OpenAI 以及微软在 AI 模型方面的成功,离不开 Twitter 数据的贡献。为此,在上周微软宣布旗下 Smart Campaigns 广告服务不再支持 Twitter 之际,马斯克便留下威胁之语,称「他们使用 Twitter 数据进行非法训练。(现在是)诉讼时间。」
StackOverflow:不是针对全员,只是针对大公司
在Stack Overflow CEOPrashanthChandrasekar 看来,"为 LLMs推波助澜的社区平台绝对应该为他们的贡献得到补偿,这样像我们这样的公司就可以重新投资回我们的社区,继续使它们蓬勃发展"。
Chandrasekar 认为,潜在的额外收入对确保 Stack Overflow 能够不断吸引用户和维持高质量的信息至关重要。他认为这也将有助于未来的聊天机器人迭代,毕竟大模型想要与时俱进,必须要"在一些最前沿的知识上训练。而 Stack Overflow 需要不断创造新的知识"。
但是,将有价值的数据圈起来也可能阻止一些人工智能的训练,并减缓 LLMs 的改进。Chandrasekar 表示,开放适当的许可只会有助于加速高质量 LLM 的发展。
不过,据 Wired 透露,此次 Stack Overflow 和 Reddit 并非是想向所有 AI 模型公司“发难”,其还是会将继续向一些人和公司免费授权数据。
Chandrasekar 表示,“Stack Overflow 只希望从本着商业目的而开发 LLM 的公司那里得到报酬。当人们开始对建立在我们这样社区之上的产品收费时,这就是不公平使用的地方。"
另外,据《纽约时报》报道,Reddit 首席执行官 Steve Huffman 称,他不想给世界上最大的公司提供免费服务。他表示,「抓取 Reddit,产生价值,却不把这些价值返还给我们的用户,这是我们有意见的地方。」
AIGC、大模型的下一步:该如何规范使用?
为此,不少业界人士认为,Stack Overflow、Reddit对其聊天数据进行收费是似乎已经成为行业一种发展趋势,这也必然会对上游 AI 大模型厂商带来一定的影响。
毕竟每个 AI 模型开发商无不在寻求降低开发大模型的巨大成本,然而,如今他们不仅需要为巨大的算力付出代价,也还要为无法计算的数据量来买单。截至目前,OpenAI、Meta、Google 等公司均未予置评。
不过,继续想想,如果 Stack Overflow、Reddit 等平台索取费用成功,对于在其平台上免费撰写问题和答案的普通用户而言,似乎也有理由要分一杯羹了。
这一场围绕大模型、AIGC 训练引发的规范、付费问题的讨论也将愈演愈烈。
参考:
https://www.wired.com/story/stack-overflow-will-charge-ai-giants-for-training-data/
https://www.zdnet.com/article/stack-overflow-joins-reddit-and-twitter-in-charging-ai-companies-for-training-data/
https://www.washingtonpost.com/technology/interactive/2023/ai-chatbot-learning/
- 0000
- 0002


 0000
0000- 0000
- 0000