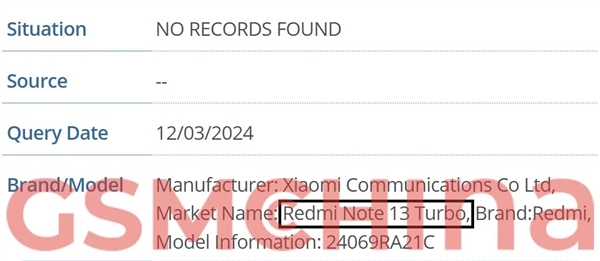
多模态大模型KOSMOS-2.5 擅长处理文本密集图像
站长网2023-09-28 10:39:200阅
随着视觉与语言的深度融合,文本图像理解成为多模态领域的新方向。文章介绍了一个突破性的多模态模型KOSMOS-2.5,它在处理文本密集图像上展现强大能力。
论文地址:https://arxiv.org/abs/2309.11419
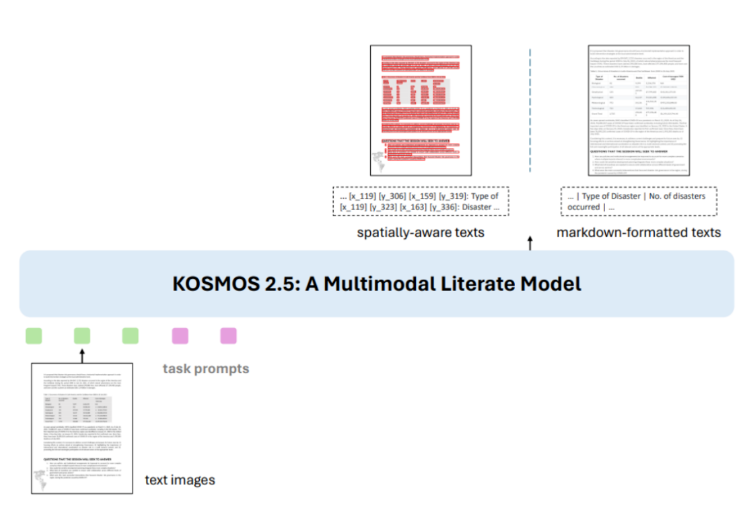
KOSMOS-2.5基于KOSMOS-2改进而来,采用统一的Transformer框架,实现文本图像的端到端理解。它包含一个视觉编码器和文本解码器,通过重采样模块连接,可以同时完成检测文本内容和坐标、生成Markdown格式文本。

Datasets是KOSMOS-2.5的关键。文章使用包含丰富文本行图像和Markdown格式文本的海量数据集进行预训练,达到3.24亿条。这种多任务联合训练增强了模型的多模态理解力。
KOSMOS-2.5在多个文本密集图像任务上展现卓越表现:端到端文档文本识别和Markdown生成,同时在少样本学习上也显现潜力。这标志着在更广泛的文本图像理解领域,KOSMOS-2.5能发挥关键作用。
展望未来,扩展模型规模以处理更多数据是关键方向。目标是进一步提升对文本图像的解释生成能力,将KOSMOS-2.5应用于更多实际场景,如文档处理、信息抽取等,从而使语言模型真正具备「读图识文」的能力。
0000
评论列表
共(0)条相关推荐
- 0000
- 0000
- 0000
- 0000
 0000
0000