Deci AI推出8.2亿参数的文本到图像潜在扩散模型DeciDiffusion 1.0
要点:
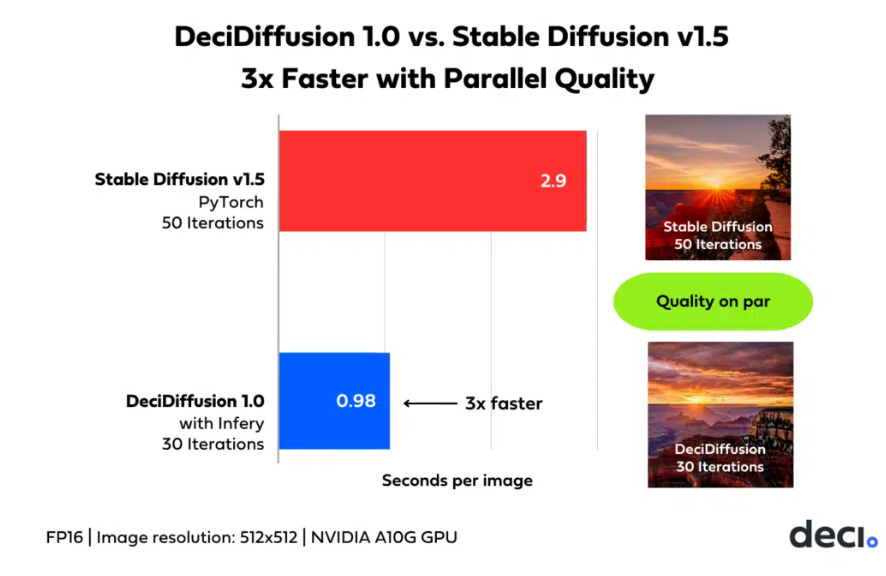
1. Deci AI推出DeciDiffusion1.0,这是一个具有8.2亿参数的文本到图像潜在扩散模型,速度比稳定扩散快3倍。
2. DeciDiffusion1.0采用创新的U-Net-NAS架构,以更高效的方式生成高质量图像,并通过四阶段的培训过程优化了样本效率和计算速度。
3. 研究团队进行了用户研究,发现DeciDiffusion1.0在图像美学方面具有优势,同时在与文本描述的匹配方面与Stable Diffusion1.5相媲美,为文本到图像生成领域带来了新的创新。
Deci AI最近推出了DeciDiffusion1.0,这是一项令人振奋的创新,旨在解决文本到图像生成领域的挑战。长期以来,将文本描述转化为栩栩如生的图像一直是人工智能领域的难题,因为这涉及到自然语言理解和视觉内容创建之间的巨大差距。研究人员一直在努力开发高效且有效的模型来实现这一目标。
DeciDiffusion1.0采用了一种全新的方法,通过一系列关键创新使其脱颖而出。其中一个关键创新是将传统的U-Net架构替换为更高效的U-Net-NAS架构。这种架构变化降低了参数数量,同时提高了性能,使得模型能够更高效地生成高质量的图像。
项目地址:https://huggingface.co/spaces/Deci/DeciDiffusion-v1-0
这个模型的训练过程也非常值得注意。它经历了四个阶段的培训过程,以优化样本效率和计算速度。这一方法对于确保模型能够在更少的迭代次数内生成图像至关重要,从而使其在实际应用中更加实用。
DeciDiffusion1.0的技术核心包括使用变分自动编码器(VAE)和CLIP的预训练文本编码器。这个组合使模型能够有效地理解文本描述并将其转化为视觉表示。该模型的一个关键成就是其能够生成高质量的图像,同时迭代次数更少。这意味着DeciDiffusion1.0在样本效率方面表现出色,能够更快地生成逼真的图像。
研究团队进行了用户研究,以评估DeciDiffusion1.0的性能。研究使用了一组10个提示,将DeciDiffusion1.0与Stable Diffusion1.5进行了比较,为美学和提示对齐提供了宝贵的见解。研究结果显示,DeciDiffusion1.0在图像美学方面具有优势。与Stable Diffusion1.5相比,DeciDiffusion1.0在30次迭代时始终生成更具吸引力的图像。然而,值得注意的是,在50次迭代时,与提供的文本描述相匹配的能力与Stable Diffusion1.5相当。这表明DeciDiffusion1.0在效率和质量之间取得了平衡。
总之,DeciDiffusion1.0是文本到图像生成领域的一项令人瞩目的创新。它解决了长期存在的问题,并提供了有希望的解决方案。通过将U-Net架构替换为U-Net-NAS并优化训练过程,研究团队创建了一个不仅能够生成高质量图像,而且在效率上更加出色的模型。用户研究结果强调了该模型的优势,特别是在图像美学方面的表现。这是使文本到图像生成更加易于访问和实用于各种应用的重要一步。尽管仍然存在挑战,如处理非英文提示和解决潜在偏见等问题,但DeciDiffusion1.0代表了将自然语言理解与视觉内容创建融合的里程碑。
这个创新证明了创新思维和先进培训技术在不断发展的人工智能领域的力量。随着研究人员继续推动AI能够实现的界限,我们可以期待进一步的突破,使我们更接近一个世界,其中文本无缝地转化为引人入胜的图像,从而在各个行业和领域带来新的可能性。
- 0000
- 0000
- 0005

 0001
0001- 0000


