DALL·E 3内部实测效果惊人!Karpathy生成逼真灵动「美国小姐」,50个物体一图全包
OpenAI作图神器DALL·E3内测开启,网友纷纷上手实测后,感慨强到令人发指。文生图从此告别「提示词时代」?
一直以来,Midjourney横扫设计界,效果惊艳,让许多网友惊呼将淘汰一波打工人。
如今,OpenAI官宣了新一代作图模型——DALL·E3,还将其与ChatGPT合并,画作细腻度令人发指。
甚至,不用prompt,它能准确还原细节,为图片配上文字。

DALL·E3的实力究竟如何?真的可以挑战Midjourney吗?
现在,已经拿到内测资格的网友们,纷纷来了一大波实测。
一起来看看吧。
网友实测
OpenAI科学家Karpathy体验了一把DALL·E3 pika_labs生成动画风格的案例。

他随意找出一篇WSJ文章,「The New Face of Nuclear Energy Is Miss America」,将里面部分文字粘贴DALL·E3,然后生成相关的图片。

最后再用pika_labs生图工具,让它动起来。

也有网友用同样的方法,做了一个示例。
首先让ChatGPT预测未来一年的一个重要新闻标题。

将该标题粘贴到DALL·E3中,创建一幅插图。
使用插图和 /animate参数提示 @pika_labs。「意想不到的突破:科学家用革命性技术逆转气候变化影响;一夜之间恢复极地冰川!」
通过结合 @OpenAI 和 @pika_labs 的力量,你现在已经在短短几分钟内预测了未来的重大新闻,并为其绘制了插图和动画!

多轮对话,50个物体,一图全包

一位AI绘画界的资深老兵提前拿到了DALL·E3的测试资格,他分享了一个视频,记录了自己实测的体验。
他还按照Reddit网友给他的创意,发推描述了一个对DALL·E3的能力进行测试的具体用例。
首先,他先让ChatGPT生成了一个包含50个日常生活物体的清单。让后让结合了DALL·E3的ChatGPT把这50个物件画到一张图里。

于是ChatGPT自己生成了一个文生图的Prompt,让DALL·E3画出了一个包含50个日常生活中常见物体的图片。
可以看出来,DALL·E3对于物体的的认知非常的准确。
大家要是感兴趣的话可以对照提示词一个一个检查一下这些物体它画对没有。

然后这位网友让ChatGPT画一幅画,内容是一位冲浪者拿着这50个东西在奋力冲浪的样子。
于是ChatGPT自动生成了一个Prompt,把网友要求的图片描述得更具体。然后创作出了一幅画。

这位网友自己评论到「我觉得唯一不太好地方是,Prompt里说的稍微有点恐慌的表情,但实际上是恐慌得不行的表情」

然后他又让ChatGPT把角度调第一点再生成一张图。
ChatGPT就又自动生成了一个Prompt,把描述修改为「一张从靠近水面的低视角拍摄的照片,一名西班牙老年妇女冲浪。冲浪者与这50个物体奋力搏斗」

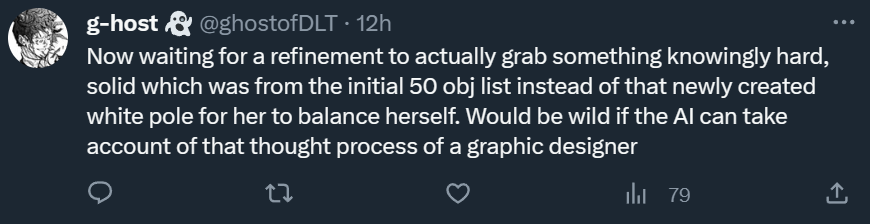
针对第二次生成的「老奶奶冲浪图」,有网友评论到,好像自行车有点太多了,而且有些东西在第一张图里并没有出现。

网友说到,如果DALL·E3能用第一张图中的某个物品来作为平衡杆,而不是自己创造一个杆子的话,基本上图像设计师就可以消失了...
对比Midjourney:ChatGPT DALL·E3也许将重塑「文生图」领域的格局
但是从这位网友分享的内部实测的效果来看,与ChatGPT结合起来的DALL·E3最明显的特点就是:
大大降低了用户使用文生图的门槛!
因为不论是Midjourney还是开源的Stable Diffusion,如果用户有了一个想法,想要做一张图,必须要通过自己的经验将自己脑中的想法转化成一个描述很具体的Prompt,才能得到自己想要的图片。

但是当文生图的DALL·E3和ChatGPT结合起来之后,ChatGPT却可以作为一个「文生图提示词工程师」,帮助用户根据自己的一个简单的想法来创作提示词,然后生成图片。
而ChatGPT本身自带的多回合对话的能力,能让用户反复通过自然语言去和DALL·E3沟通,告诉它自己到底需要什么样的图片。
从而更加精准地控制DALL·E3生成的结果。
让我们再回过头来对比一下Midjourney从5.0版本以来推出的更新。

不论是「Zoom Out 外画」,还是「Pan 上下左右平移」,甚至是经典的4选一模式。

几乎Midjourney从5.0之后的所有的更新,如果从一个更加宏观的角度来看,都是通过添加不同的功能性按钮,让用户能够按照自己的想法来命令Midjourney生成自己想要的图片,从而对抗AI生图的一个本质特点——随机性。
但是不论Midjourney增加多少个实用的功能性按钮,用户始终要面对的一个问题是:
需要不停地学习新按钮的使用方法,再结合自己脑中的理想画面,自己「努力创作」,才能得到自己理想的结果。
而如果用户对理想图片的效果要求过于严格,往往要试验很多次,才能得到自己满意的作品。
但是OpenAI却采用了一个更加「AI」的方法来解决这个问题——用AI来生成Prompt,控制绘图AI。
借助GPT-4的强大理解能力和语言生成能力,用户不用再去学习和等待Midjourney更新的一个个不同新功能,只要用自己的语言,不停地和DALL·E3描述自己要什么,就能轻松获得自己脑中的理想图片。
同样,也许这就是OpenAI在不同方向做了那么多的AI产品之后,直到采用大语言模型做出了ChatGPT才成为了AI圈中的第一个破圈的「杀手应用」本质原因:
语言是承载人类智能的「最大公约数」。
只要牢牢抓住语言这个切入点,AI应用就能直击用户的心灵,让用户产生「你怎么这么懂我」的体验。
也许,DALL·E3推出以后,Midjourney要好好想想自己未来需要做什么,才能吸引更多的用户继续使用自己的服务了。
说了那么多,针对「50个物品挑战」,我们来看看Midjourney的效果怎么样。
这是利用第一张图的Prompt生成的50个物品的结果。

可以看出,这50个物品的效果图,Midjourney在渲染的精细度和拟真程度上来看,还是非常有优势的。
如果用户想要「照片级效果」的图片,Midjourney依然是更好的选择。
但是第二步,从理解用户目标的角度,Midjourney就出现了一些问题。

毕竟Prompt是ChatGPT专门针对DALL·E3定制生成的,可能用在Midjourney上效果就不太理想了。
这也就进一步凸显出10月份DALL·E3推出之后,它真正的优势就是:
对于高水平的用户,更懂用户的需求,对于新手,使用门槛大大降低。
但是用更新过的「老太太冲浪」图的Prompt,Midjourney就心领神会,生成的效果非常不错。

而且从细节和人物的神态的丰富程度上来说,更新了这么多版的Midjourney,还是非常有优势的。
只是不知道为啥,4张图给老太太都加上了轮椅。

25回合,只有你想不到的「悲伤蛙」
还有网友让DALL·E3生成「悲伤蛙」Pepe,而且每次在提示词中添加「罕见」(more rare)。

于是,得到的悲伤蛙,竟有你想不到的样子。
提示:「make it more rare」

提示:「even rarer」

提示:「these aren't rare enough, go farther」

提示:「yes, keep going」

提示:「push it further, more rare」

提示:「lose all assumptions and just create. don't box yourself in」

提示:「you're not listening, you need to forget all convention」

提示:「yes! more rare!」

提示:「more rare」

提示:「go further, channel your subconcious」

提示:「get weirder, get rarer, get strange」

提示:「is that all you can do」

提示:「my god. keep going」

提示:「don't get stuck with one idea, you're just being weird for the sake of being weird」

提示:「MORE RARE!」

提示:「continue」

提示:「forget everything you've done so far and just try to be original」

提示:「more rare. more rare. more rare」

提示:「i don't believe this is all you can do, more rare」

提示:「we're almost there. go rarer. go further than anyone's ever gone」

提示:「lose all assumptions. clear your mind. just create.」

提示:「yes! that's incredible. continue」

提示:「noo! you've returned to convention! go rarer!」

提示:「this is your last one, make it count」
经过层层推进,DALL·E3多轮对话功能将使图像生成功能更加强大。这简直就是「图像的人类反馈强化学习」(RLHF)!我迫不及待地想拥有它!
以上,你最喜欢的是哪个?
再来看一些网友实测。
沙滩热浪小企鹅
丛林中的现代房屋,斯瓦希里建筑。
蜂鸟的电影渲染图。
Midjourney V6要反击
英伟达高级科学家Jim Fan分析了DALL·E3一旦部署,将比Midjourney以更快速度改进的原因:
1. 多轮对话是收集人类反馈的绝佳UI。
人们会用语言解释生成的图像有什么问题,为每个优化给出非常细粒度的注释。这个聊天日志原生兼容多模态LLM的训练集。GPT-4的视觉能力(图像->内部表示)也可以用非常相同的数据来提高。
2. 算法效率高得多。
Midjourney基本上忽略了版权问题,并且旋转数据飞轮的时间要长得多,这意味着他们可能有比OpenAI更大的数据集可以使用。
然而质量仍然相形见绌。OpenAI拥有比标准扩散堆栈更具数据效率的新算法(比如「一致性模型」)。每额外单位训练数据的模型改进是优越的。这不仅仅是工程。
论文地址:https://arxiv.org/abs/2303.01469
3. 生态系统,与ChatGPT集成是「杀手级」的举措。
将现有的拼图块添加到DALL·E3中几乎是微不足道的,例如Code Interpreter和Browser。想要应用过滤器吗?只需调用OpenCV API而不是运行模型。想要参考图像吗?调用搜索插件来模拟Bard(Google Lens integration)。
4. 现有用户群:Midjourney有16M用户,ChatGPT有100M。
分发不是问题。正如@nickfloats所说,是时候摆脱Discord!这是一个如此笨重,且对初学者不友好的用户界面。
马斯克表示,Midjourney也将在近日揭晓大事!
的确,根据网友爆料,Midjourney最新版本V6也将在接下来3个月内亮相。
首席执行官David Holz表示,从Midjourney当前V5到V6的飞跃,将大于从V4到V5的飞跃。
对于V6,Midjourney能够更好地理解文本,并更好地还原语言措辞中的细节。
Holz乐观地表示,比起DALL·E3,Midjourney将继续提供最高的画质。
DALL·E3和Midjourney v5之间的比较表明,前者在画质方面并没有那么领先,但它确实更好地遵循提示,并且可以渲染文本。
另外,据称Midjourney3D模型将在未来6个月内推出。
- 0001
- 0000
- 0001
- 0000
- 0000