1.5T内存挑战英伟达!8枚芯片撑起3个GPT-4,华人AI芯片独角兽估值365亿
高端GPU持续缺货之下,一家要挑战英伟达的芯片初创公司成为行业热议焦点。
8枚芯片跑大模型,就能支持5万亿参数(GPT-4的三倍)。
这是独角兽企业SambaNova刚刚发布的新型AI芯片SN40L——
型号中40代表是他们第四代产品,L代表专为大模型(LLM)优化:高达1.5T的内存,支持25.6万个token的序列长度。
CEORodrigo Liang表示,当前行业标准做法下运行万亿参数大模型需要数百枚芯片,我们的方法使总拥有成本只有标准方法的1/25。
SambaNova目前估值50亿美元(约365亿人民币),累计完成了6轮总计11亿美元的融资,投资方包括英特尔、软银、三星、GV等。
他们不仅在芯片上要挑战英伟达,业务模式上也说要比英伟达走的更远:直接参与帮助企业训练私有大模型。
目标客户上野心更是很大:瞄准世界上最大的2000家企业。
1.5TB内存的AI芯片
最新产品SN40L,由台积电5纳米工艺制造,包含1020亿晶体管,峰值速度638TeraFLOPS。
与英伟达等其他AI芯片更大的不同在于新的三层Dataflow内存系统。
520MB片上SRAM内存
65GB的高带宽HBM3内存
以及高达1.5TB的外部DRAM内存

与主要竞品相比,英伟达H100最高拥有80GB HBM3内存,AMD MI300拥有192GB HBM3内存。
SN40L的高带宽HBM3内存实际比前两者小,更多依靠大容量DRAM。
Rodrigo Liang表示,虽然DRAM速度更慢,但专用的软件编译器可以智能地分配三个内存层之间的负载,还允许编译器将8个芯片视为单个系统。
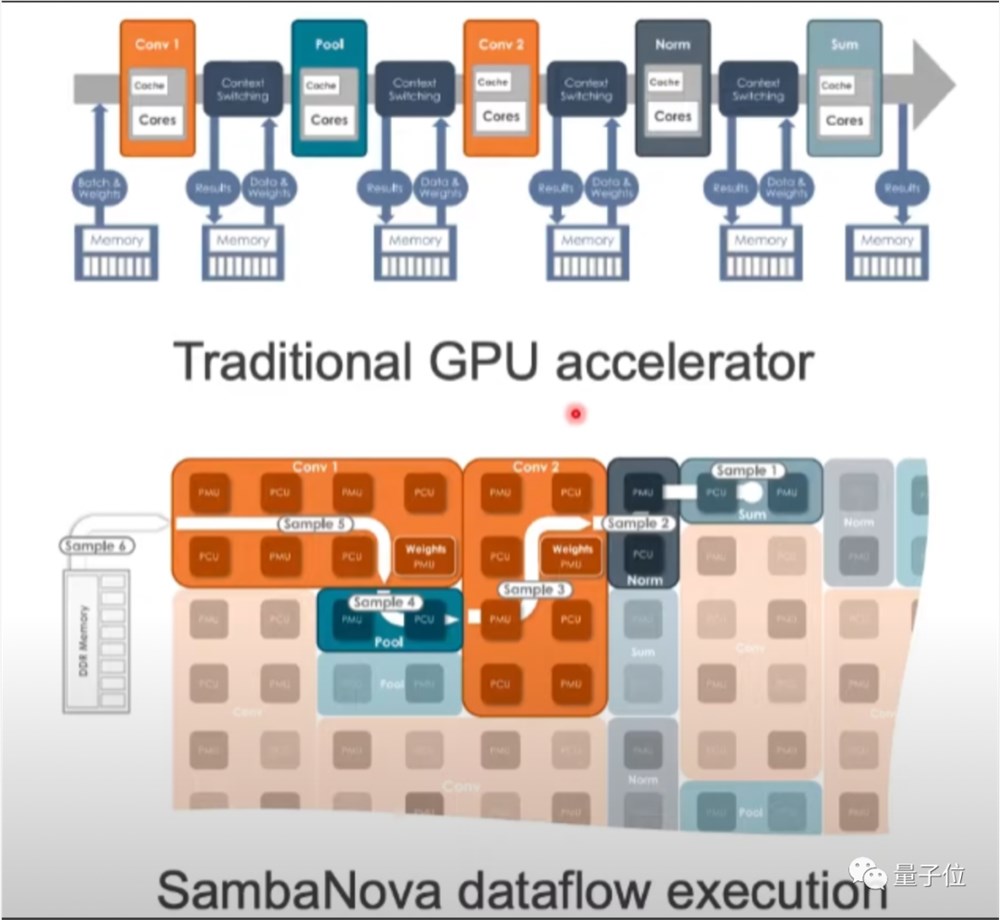
除了硬件指标,SN40L针对大模型做的优化还有同时提供密集和稀疏计算加速。
他们认为大模型中许多权重设置为0,像其他数据一样去执行操作很浪费。
他们找到一种软件层面的加速办法,与调度和数据传输有关,但没有透露细节,“我们还没准备好向公布是如何做到这一点的”。
咨询机构Gartner的分析师Chirag Dekate认为,SN40L的一个可能优势在于多模态AI。
GPU的架构非常严格,面对图像、视频、文本等多样数据时可能不够灵活,而SambaNova可以调整硬件来满足工作负载的要求。
目前,SambaNova的芯片和系统已获得不少大型客户,包括世界排名前列的超算实验室,日本富岳、美国阿贡国家实验室、劳伦斯国家实验室,以及咨询公司埃森哲等。
业务模式也比较特别,芯片不单卖,而是出售其定制技术堆栈,从芯片到服务器系统,甚至包括部署大模型。
为此,他们与TogetherML联合开发了BloomChat,一个1760亿参数的多语言聊天大模型。
BloomChat建立在BigScience组织的开源大模型Bloom之上,并在来自OpenChatKit、Dolly2.0和OASST1的OIG上进行了微调。
训练过程中,它使用了SambaNova独特的可重配置数据流架构,然后在SambaNova DataScale系统进行训练。
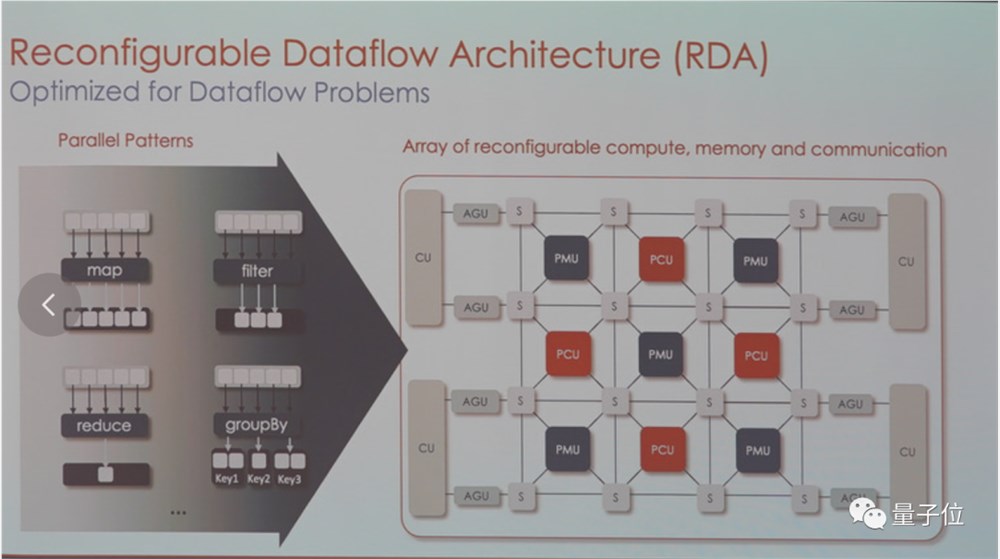
这也是这家公司最大被投资者热捧之外的最大争议点之一,很多人不看好一家公司既做芯片又做大模型。
给每家大企业打造150个大模型
在与The Next Platform网站交流时,CEO Rodrigo Liang表示:
用于大模型训练的公开数据已快耗尽,但对参数数量的追求还在不断增加。
各种大模型的性能相差只有几个百分点,这不是大家应该玩的游戏。
他认为大模型与生成式AI商业化的下一个战场是企业的私有数据,尤其是大企业。
这些企业坐拥大量的数据,但自己不知道其中大部分内容是什么。
对于企业私有大模型的形态,SambaNova也有与众不同的观点。
他们认为最终企业内部不会运行一个GPT-4或谷歌Gemini那样的超大模型,而是根据不同数据子集创建150个独特的模型,聚合参数超过万亿。
相当于把GPT-4等大模型内部的Mixture of Experts(专家混合)架构扩展到整个系统,称为Composition of Experts(专家合成)。
在企业运转的每个节点运行一个完整且经过专门调整的基础模型,分别用法律语料库、制造语料库、风险管理语料库、财富管理语料库、客户销售语料库、客户支持语料库等等不同数据训练。
这些专家模型之间通过一种软件路由或负载平衡器联在一起,收到推理请求后决定具体向哪个模型推送提示词。
这一策略与GPT-4和谷歌Gemini等做法形成鲜明对比,巨头大多希望创建一个能泛化到数百万个任务的巨型模型。
分析师认为技术上可能谷歌的做法性能更强,但SambaNova的方法对企业来说更实用。
没有任何一个模型或人能完整访问企业的所有数据,限制每个部门能访问的专家模型,就能限制他们能访问的数据。
斯坦福系芯片公司,华人工程师主力
SambaNova成立于2017年,2020年之前都比较低调。
联创3人都是斯坦福背景,连产品系列名Cardinal(深红色)都是斯坦福的昵称与代表颜色。
CEO Rodrigo Liang是前Sun/甲骨文工程副总裁,也有人将这个名字解读为暗指甲骨文老对头IBM的DeepBlue(深蓝)。
CTOKunle Olukotun是电气工程教授,因多核芯片架构方面的研究而闻名,开发了首批支持线程级推测 (TLS) 的芯片之一。
Christopher Ré是计算机科学副教授,重点研究方向机器学习和数据分析的速度和可扩展性。
此外团队中还有不少华人工程师。
从官网公开信息来看,SambaNova的领导团队中,至少有3名华人。
Jonathan Chang,拥有UC伯克利的机械工程学士学位以及南加州大学的MBA学位。
他在构建高增长方面拥有20多年的经验。加入SambaNova之前,Chang在特斯拉工作了近9年。
Marshall Choy,此前曾担任甲骨文公司系统产品管理和解决方案开发副总裁,监督了数十个行业的企业硬件和软件产品的上市。
Penny Li,在EDA工具和微处理器设计方面拥有超过27年的经验。此前,她曾在IBM和甲骨文工作过。
如果去领英搜索还能发现更多华人团队成员。
目前SambaNova包含SN40L芯片的人工智能引擎已上市,但定价没有公开。
根据Rodrigo Liang的说法,8个SN40L组成的集群总共可处理5万亿参数,相当于70个700亿参数大模型。
全球2000强的企业只需购买两个这样的8芯片集群,就能满足所有大模型需求。
参考链接:
[1]https://spectrum.ieee.org/ai-chip-sambanova
[2]https://www.nextplatform.com/2023/09/20/sambanova-tackles-generative-ai-with-new-chip-and-new-approach/
[3]https://sambanova.ai/resources/
- 0000
- 0000

 0000
0000- 0000
- 0003



