视觉Transformer中ReLU替代softmax,DeepMind新招让成本速降
Transformer 架构已经在现代机器学习领域得到了广泛的应用。注意力是 transformer 的一大核心组件,其中包含了一个 softmax,作用是产生 token 的一个概率分布。softmax 有较高的成本,因为其会执行指数计算和对序列长度求和,这会使得并行化难以执行。
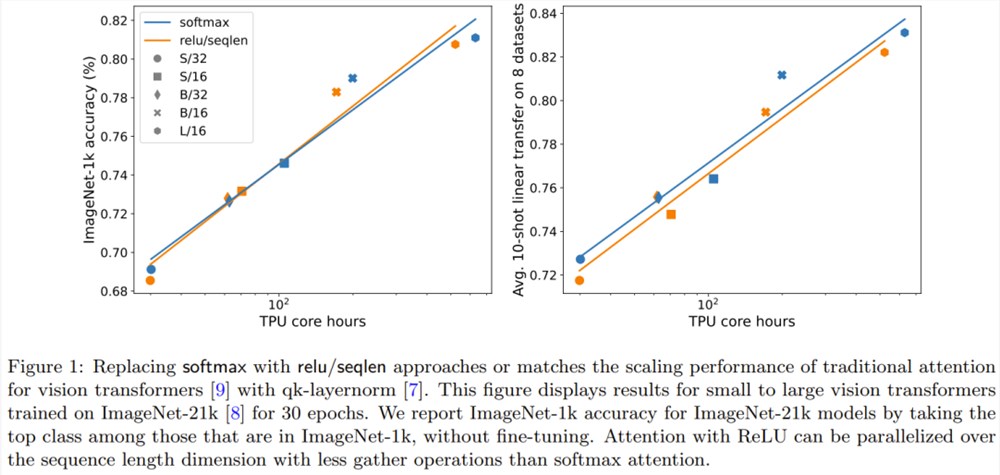
Google DeepMind 想到了一个新思路:用某种不一定会输出概率分布的新方法替代 softmax 运算。他们还观察到:在用于视觉 Transformer 时,使用 ReLU 除以序列长度的注意力可以接近或匹敌传统的 softmax 注意力。

论文:https://arxiv.org/abs/2309.08586
这一结果为并行化带来了新方案,因为 ReLU 注意力可以在序列长度维度上并行化,其所需的 gather 运算少于传统的注意力。
方法
注意力
注意力的作用是通过一个两步式流程对 d 维的查询、键和值 {q_i, k_i, v_i} 进行变换。
在第一步,通过下式得到注意力权重
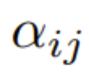
:
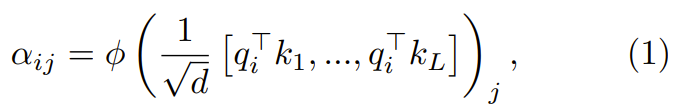
其中 ϕ 通常是 softmax。
下一步,使用这个注意力权重来计算输出
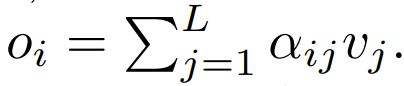
这篇论文探索了使用逐点式计算的方案来替代 ϕ。
ReLU 注意力
DeepMind 观察到,对于1式中的 ϕ = softmax,
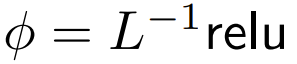
是一个较好的替代方案。他们将使用
的注意力称为 ReLU 注意力。
已扩展的逐点式注意力
研究者也通过实验探索了更广泛的

选择,其中 α ∈ [0,1] 且 h ∈ {relu,relu² , gelu,softplus, identity,relu6,sigmoid}。
序列长度扩展
他们还观察到,如果使用一个涉及序列长度 L 的项进行扩展,有助于实现高准确度。之前试图去除 softmax 的研究工作并未使用这种扩展方案。
在目前使用 softmax 注意力设计的 Transformer 中,有

,这意味着

尽管这不太可能是一个必要条件,但
能确保在初始化时
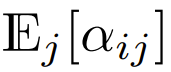
的复杂度是

,保留此条件可能会减少替换 softmax 时对更改其它超参数的需求。
在初始化的时候,q 和 k 的元素为 O (1),因此

也将为 O (1)。ReLU 这样的激活函数维持在 O (1),因此需要因子

才能使
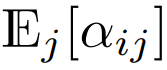
的复杂度为
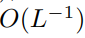
。
实验与结果
主要结果
图1说明在 ImageNet-21k 训练方面,ReLU 注意力与 softmax 注意力的扩展趋势相当。X 轴展示了实验所需的内核计算总时间(小时)。ReLU 注意力的一大优势是能在序列长度维度上实现并行化,其所需的 gather 操作比 softmax 注意力更少。
序列长度扩展的效果
图2对比了序列长度扩展方法与其它多种替代 softmax 的逐点式方案的结果。具体来说,就是用 relu、relu²、gelu、softplus、identity 等方法替代 softmax。X 轴是 α。Y 轴则是 S/32、S/16和 S/8视觉 Transformer 模型的准确度。最佳结果通常是在 α 接近1时得到。由于没有明确的最佳非线性,所以他们在主要实验中使用了 ReLU,因为它速度更快。

qk-layernorm 的效果
主要实验中使用了 qk-layernorm,在这其中查询和键会在计算注意力权重前被传递通过 LayerNorm。DeepMind 表示,默认使用 qk-layernorm 的原因是在扩展模型大小时有必要防止不稳定情况发生。图3展示了移除 qk-layernorm 的影响。这一结果表明 qk-layernorm 对这些模型的影响不大,但当模型规模变大时,情况可能会不一样。

添加门的效果
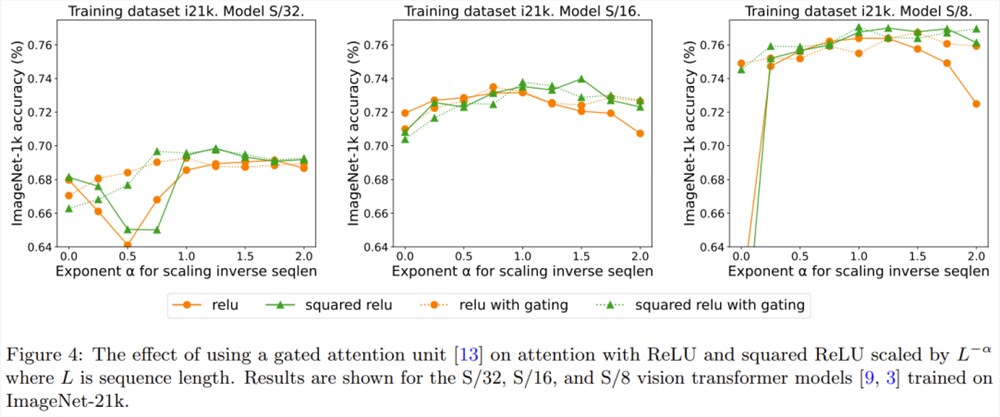
先前有移除 softmax 的研究采用了添加一个门控单元的做法,但这种方法无法随序列长度而扩展。具体来说,在门控注意力单元中,会有一个额外的投影产生输出,该输出是在输出投影之前通过逐元素的乘法组合得到的。图4探究了门的存在是否可消除对序列长度扩展的需求。总体而言,DeepMind 观察到,不管有没有门,通过序列长度扩展都可以得到最佳准确度。也要注意,对于使用 ReLU 的 S/8模型,这种门控机制会将实验所需的核心时间增多大约9.3%。
- 0001
- 0000
- 0000
- 0001
- 0001