“苹果入局大模型?我深挖到了一些细节”
在今年早些时候的 WWDC 上,苹果宣布即将推出的 iOS 和 macOS 版本将配备一项由 “Transformer 语言模型”提供支持的新功能,这个功能和很多 AIGC 工具一样,方便用户在输入文字时,提供由 AI 生成的文本建议。
听到这个消息后,我很好奇这个功能是如何工作的。尽管大多数竞争对手在过去几年里都在全力开发大型语言模型,但苹果公司并没有部署很多自己的语言模型。我认为这是因为苹果公司通常以前沿和追求完美而自豪,而现阶段的语言模型都相当粗糙和不完美。
因此,这是苹果首次公布大模型的消息,他们也有计划在最新的 iOS、MacOS 操作系统上率先试水。这让我对该功能产生了一些疑问,特别是:
该功能的底层模型是什么?
它的架构是什么?
使用了哪些数据来训练模型?
在花了一些时间思考这些问题后,我找到了一些答案,但许多细节仍然不清楚。如果您能找到答案,请与我联系!
该功能如何运作?
安装 macOS beta 后,我立即打开 Notes 应用程序并开始打字。尽管尝试了许多不同的句子结构,但该功能的出现频率通常低于我的预期。它主要是完成单个单词。

该功能有时也会一次建议多个单词,但这通常仅限于即将出现的单词非常明显的情况,类似于 Gmail 中的自动完成功能。

我们可以更深入地挖掘吗?
找到模型本身有点困难,但我最终发现 AppleSpell 使用了该模型,AppleSpell 是一个内部 macOS 应用程序,可以在打字时检查拼写和语法错误。在 xpcspy 的帮助下,我编写了一个 Python 脚本,该脚本可以监听 AppleSpell 活动,并在在任何应用程序中键入时从预测文本模型中传输最可能的建议。
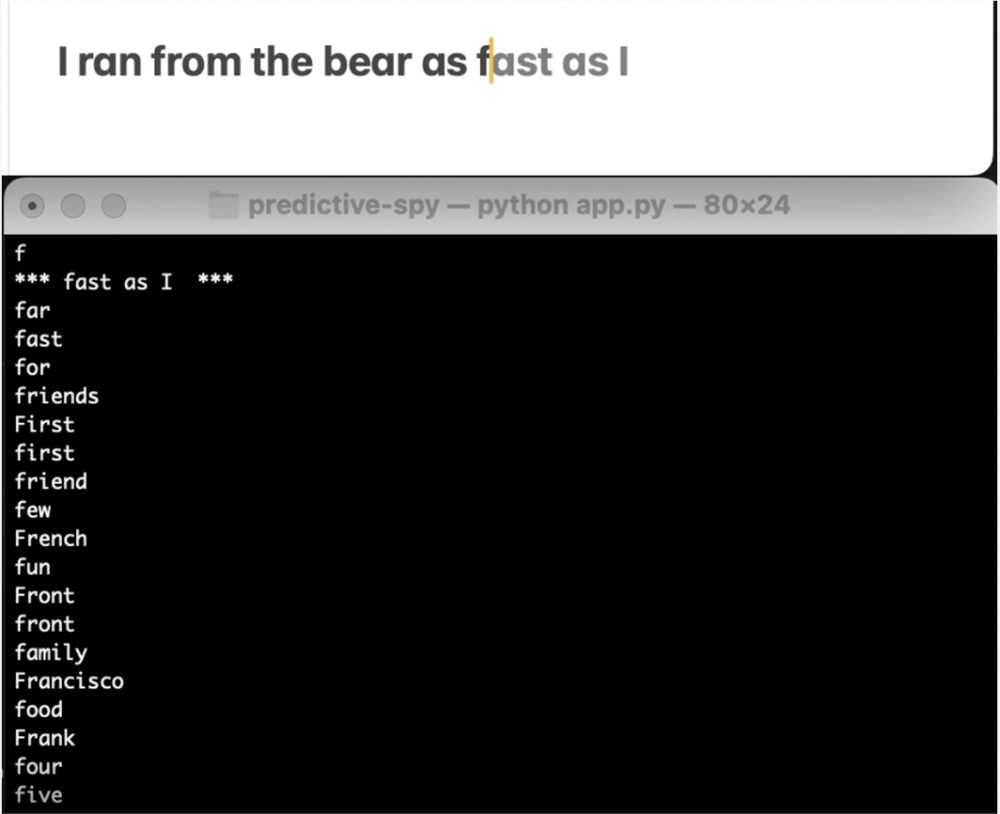
不幸的是,我在夏天早些时候在第一个 macOS Sonoma beta 上编写了这个脚本。在随后的测试版之一(我不确定是哪一个)中,Apple 从 AppleSpell 发送的 XPC 消息中删除了未使用的补全。我无法从这些完成中收集太多有关模型行为的信息,但这仍然是一个很酷的发现。
模型在哪里?
经过更多挖掘后,我很确定我在 /System/Library/LinguisticData/RequiredAssets_en.bundle/AssetData/en.lm/unilm.bundle 中找到了预测文本模型。该捆绑包包含在键入时使用的多个 Espresso 模型文件(Espresso 似乎是在模型上运行推理的 CoreML 部分的内部名称)。我最终无法对模型进行逆向工程,但我相当有信心这是保存预测文本模型的地方。原因如下:
unilm.bundle 中的许多文件在 macOS Ventura (13.5) 上不存在,但在 macOS Sonoma beta (14.0) 上确实存在。两个版本中确实存在的文件都已在索诺玛中更新。
sp.dat 是 unilm.bundle 中的文件之一,存在于 Ventura 上,但已在 Sonoma beta 中更新。在该文件的更新版本中,我发现看起来非常明显像是标记器的一组标记。
sp.dat 中的标记数量与 unilm_joint_cpu.espresso.shape 和 unilm_joint_ane.espresso.shape(ANE = Apple Neural Engine)中输出层的形状相匹配,unilm.bundle 中的两个文件描述了 Espresso/CoreML 模型。这就是我们期望看到的经过训练来预测下一个标记的模型。
预测文本模型的 tokenizer
我在 unilm.bundle/sp.dat 中发现了一组15,000个标记,很明显它们构成了大型语言模型的词汇集。于是我编写了一个脚本,可以用它来亲自查看这个词汇文件。
词汇表以 <pad>、<s>、</s> 和 标记开头,这些标记都是相当常见的特殊标记(roberta-base 和 t5-base 是两种流行的语言模型):

接下来是以下序列:
20个特殊 token ,名为 UniLMCTRL0到 UniLMCTRL19
79次缩减(I’d, couldn’t, you’ve…)
1个特殊 _U_CAP_ token
20个特殊 token,名为 _U_PRE0_ 到 _U_PRE19_
60个特殊 token,名为 _U_NT00_ 到 _U_NT59_
100个表情符号
然后是一个看起来更正常的列表,包含14,716个 token,其中大多数后面跟着特殊字符 (U 9601),该字符常用于字节对编码 (BPE) tokenizer,例如 GPT-2tokenizer , 表示一个空格。
我不得不说,这个词汇文件让我觉得非常独特,但对于在此设置中部署的语言模型来说,这绝对不是不可能的。我个人从未见过表情符号在语言模型的 tokenizer 中如此突出,但现有研究表明特定领域的模型和 tokenizer 可以极大地提高下游模型的性能。因此,经过训练用于文本消息等内容(其中会大量使用表情符号和缩写)的模型会优先考虑它们,这是有道理的。
模型架构
根据前面 unilm_joint_cpu 模型的内容,我们可以对预测文本网络做出一些假设。尽管它从2019年开始共享 Microsoft UniLM 的名称,但在我看来,它更像是基于 GPT-2的模型。
GPT-2有四个主要部分:token 嵌入、位置编码、一系列12-48解码器块和输出层。unilm_joint_cpu 描述的网络似乎是相同的,只是只有6个解码器块。每个解码器块中的大多数层都有类似 gpt2_transformer_layer_3d 的名称,这似乎也表明它基于 GPT-2架构。
根据我根据每层大小的计算,Apple 的预测文本模型似乎有大约3400万个参数,并且它的隐藏大小为512个单位。这使得它比 GPT-2的最小版本还要小得多。
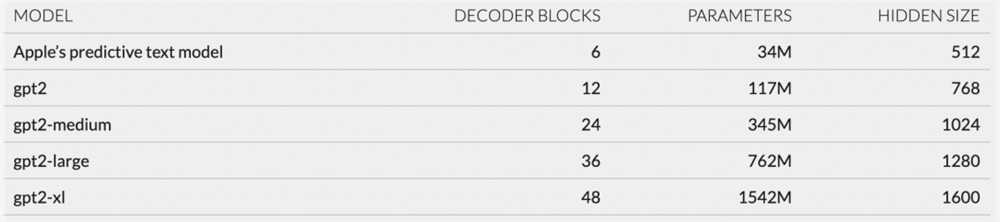
对于预测文本功能的有限范围,这对我来说是有意义的。苹果想要一种能够非常快速、非常频繁地运行的模型,而不会耗尽设备的大量电池。当我测试预测文本功能时,建议几乎在我输入时立即出现,从而带来了出色的用户体验。虽然模型的大小有限意味着它不能很好地编写完整的句子或段落,但当它对下一个或两个单词表现出非常高的置信度时,它们可能足以向用户提供建议。
然而,通过我的脚本来监听 AppleSpell 的活动,我们无论如何都可以让模型写出完整的句子。如果我输入“今天”作为句子的第一个单词,并每次都采用模型的最佳建议,这就是我得到的结果:
Today is the day of the day and the day of the week is going to be a good thing I have to do is get a new one for the next couple weeks and I think I have a lot of…
不太鼓舞人心。我们可以将其与最小 GPT-2模型的输出进行比较:
Today, the White House is continuing its efforts against Iran to help the new President, but it will also try to build new alliances with Iran to make more…
或者最大的 GPT-2模型:
Today, the U.S. Department of Justice has filed a lawsuit against the city of Chicago, the Chicago Police Department, and the city’s Independent Police Review Authority, alleging that the police department and the Independent Police Review Authority engaged in a pattern or practice…
看到所有这些额外参数的效果真是太酷了!我很好奇这个功能在未来如何发展和演变,以及苹果是否决定保持其范围狭窄或有一天扩大其功能,这将会很有趣。
如果您有兴趣亲自尝试其中任何一个,我的所有代码都在 GitHub:https://github.com/jackcook/predictive-spy
- 0000
- 0000
 0000
0000
 0000
0000

 0000
0000