AI视野:文心一言软件著作权获批;万兴科技发布大模型 “天幕”;Bing Chat确认100%采用GPT-4
📰🤖📢AI新鲜事
百度文心一言软件著作权获批
9月13日,百度“文心一言软件”著作权获批,8月31日向全社会开放,用户可以在应用商店下载使用。

要点:
1.9月13日,百度“文心一言软件”著作权获批,当前版本为V1.0.0。
2.8月31日,百度文心一言APP向全社会开放,用户可以下载APP或访问官网使用。
3. 文心一言开放后迅速成为应用商店下载榜首,是首个中文AI原生应用登顶。
Bing Chat创意和精确模式全面采用GPT-4
微软搜索主管Mikhail Parakhin确认Bing Chat在创意和精确模式下100%采用GPT-4。微软同时使用多种语言模型,还包括GPT-4Prometheus和自有的图灵语言模型。尽管大力宣传AI聊天和GPT-4,但微软在与Google的激烈竞争中仍需继续努力以提高市场份额。
要点:
1. 微软搜索主管确认Bing Chat在创意和精确模式下100%采用GPT-4。
2. 微软同时使用多种语言模型,包括GPT-4Prometheus和自有的图灵语言模型。
3. 尽管大力宣传AI聊天和GPT-4,微软仍需在与Google的竞争中继续努力。
网友用AI复现电影名场面!Midjourney Gen2,7步完成「芭本海默」
在前两天芭比海默全网爆火之后,不断有网友“复现”用MidJourney Gen-2制作电影的神技!一网友甚至晒出教程,称自己使用Midjourney和Gen-2在7步内完成类似电影「芭比海默」的动画短片制作流程,并分析了目前这种生成方式的优势和局限性。

要点:
利用ChatGPT编写剧本和字幕,Midjourney生成图片,再用Gen-2让图片动起来,最后合成就可完成类「芭比海默」短片。
现阶段 biggest难点在于Gen-2生成的人脸比较容易畸变,需要多次尝试找到较好效果。
如果未来Gen-2能够跟prompt描述连动,制作复杂剧情的生成电影将可实现。
老黄自曝:3个月卖出800吨H100的英伟达是一个“三无”公司
有分析公司算出来,英伟达最新GPU产品H100仅三个月时间就销售超过816吨。然而市值已超万亿的英伟达,竟是一个「无计划、无汇报、无层级」的公司。
要点:
英伟达H100GPU三个月内销量超过816吨,如果保持现在的销售速度,今年全年可销售3266吨。
英伟达CEO黄仁勋采取扁平化管理、不做状态报告、重视员工想法的方式领导公司。
目前全球对英伟达H100GPU需求巨大,但供不应求,各大科技公司与云服务商争相购买中。
谷歌修改“有用内容更新”政策 调整对AI生成内容的立场
谷歌最近更新了"有用内容"政策,调整了对AI生成内容的立场。这是该政策自2022年8月推出以来的第三次迭代。本次更新强调内容应该以人为本,而不仅仅是为搜索引擎而生成。谷歌表示会与OpenAI等公司合作,以帮助用户识别内容的来源。可以预见,AI生成的内容在网络上的比例会不断增加。
要点:
1、谷歌调整了有用内容政策,改变了对AI生成内容的立场,强调内容应该以人为本。
2、谷歌承认监管AI生成内容存在困难,将与OpenAI等公司合作以帮助用户识别内容来源。
3、可以预见,AI生成的内容在网络上的比例会持续增加。
全球首台AI汽车机器人“极越01”9月19日开启预订
极越汽车宣布将于9月19日推出全球首款AI汽车机器人极越01,开启限时预订,该车将成为中国首款搭载高通骁龙8295智舱芯片的车型。

要点:
1. 极越01是全球首款AI汽车机器人,将于9月19日首发亮相并开启预订。
2. 极越01将成为中国首发搭载高通骁龙8295智舱芯片的车型。
3. 极越01将基于SEA浩瀚架构,并由文心一言等AI技术全面赋能。
英国法官用ChatGPT撰写裁决文件 狂赞:非常有用
英国法官首次公开承认使用ChatGPT撰写法庭裁决书,称其“非常有用”,他透露,他直接将ChatGPT生成的文字复制并粘贴到自己的裁决中。这一言论被认为是英国法官首次承认在工作中使用生成式人工智能软件的案例。

图源备注:图片由AI生成,图片授权服务商Midjourney
要点:
1、英国上诉法院法官Birss透露使用ChatGPT撰写知识产权相关裁决书。
2、他直接将ChatGPT生成内容复制粘贴,称其“非常有用”。
3、此举引发争议,ChatGPT可能生成错误信息,美国法官曾因使用它受批评。
《纽约时报》也开始招聘擅长生成式AI工具的高级编辑
《纽约时报》正在招聘一名高级编辑,负责将生成式人工智能工具引入其新闻编辑室,以确保时报成为该领域的领导者。该编辑还将制定使用GenAI的指导方针,平衡创新与风险。
要点:
1、纽约时报招聘高级编辑,负责引入生成式AI到新闻编辑室
2、编辑要确保时报成为GenAI创新及应用的领导者
3、还将制定使用GenAI的指导方针,平衡创新与风险
微软推M365Copilot早期访问计划,为澳大利亚机构引入AI生产力工具
微软宣布澳大利亚首批客户获得Microsoft365Copilot早期访问计划资格,该服务将大型语言模型与Microsoft365数据结合,为企业带来强大的AI生产力增强。
要点:
1. 澳大利亚多家企业如AGL、Data#3、NAB等获得M365Copilot早期访问资格。
2. 金融服务业将是M365Copilot技术最快采纳行业之一。
3. 能源和公用事业企业也开始试点该服务,以提高工作效率。
👨💻💡🎯聚焦开发者
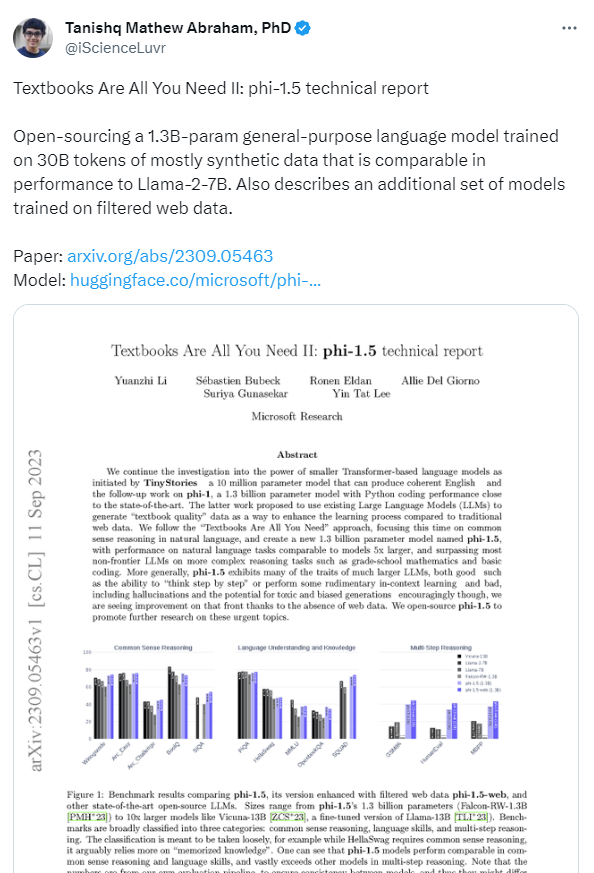
微软推出全新预训练模型phi-1.5仅13亿参数常识推理碾压Llama2
微软研究人员推出了一个仅有13亿参数的LLM模型Phi-1.5。结果表明,它在多个常识推理任务上优于参数量是其10倍以上的模型。这说明高质量数据比模型规模更为重要。
论文地址:https://arxiv.org/abs/2309.05463
项目地址:https://huggingface.co/microsoft/phi-1_5
要点:
1、微软研究人员推出了一个仅有13亿参数的LLM模型Phi-1.5。
2、Phi-1.5在常识推理任务上表现优异,优于多个参数量十倍以上的模型。
3、研究表明,模型参数规模不是决定性因素,高质量数据更为重要。
谷歌提出生成式图像动力学:让静态图片动起来
谷歌团队提出“生成图像动力学”技术,可以将静态图片转换成动态无缝循环视频,以及让用户与图片中的对象进行交互。

项目地址:https://generative-dynamics.github.io/#demo
要点:
1. 从包含自然运动的视频中提取运动轨迹,训练获得图像动力学先验模型。
2. 对输入图片预测像素级长期运动表示,转换为密集运动轨迹,生成视频。
3. 支持用户通过拖拽交互,场景会根据点的位置和方向产生对应运动。
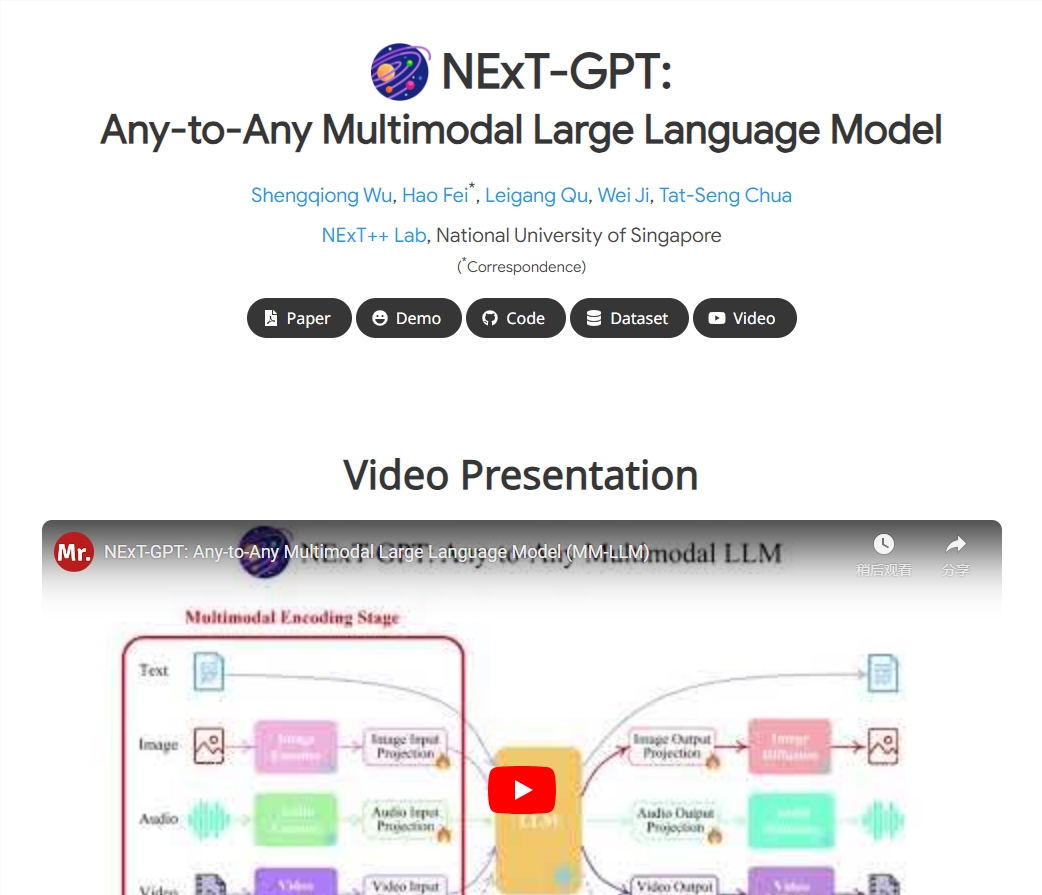
新加坡华人团队开源全能「大一统」多模态大模型NExT-GPT
新加坡国立大学华人团队开源全能多模态大模型NExT-GPT,支持任意模态输入和输出,实现文本、图像、语音、视频之间的转换。
项目地址:https://next-gpt.github.io
代码地址:https://github.com/NExT-GPT/NExT-GPT
论文地址:https://arxiv.org/abs/2309.05519
要点:
1. NExT-GPT支持任意模态的输入和输出,实现了从任一模态到任一模态的转换。
2. NExT-GPT通过组合开源的编码器、语言模型和解码器实现了全能的多模态能力。
3. NExT-GPT实现了端到端的训练和指令微调,具有较好的多模态表示对齐能力。
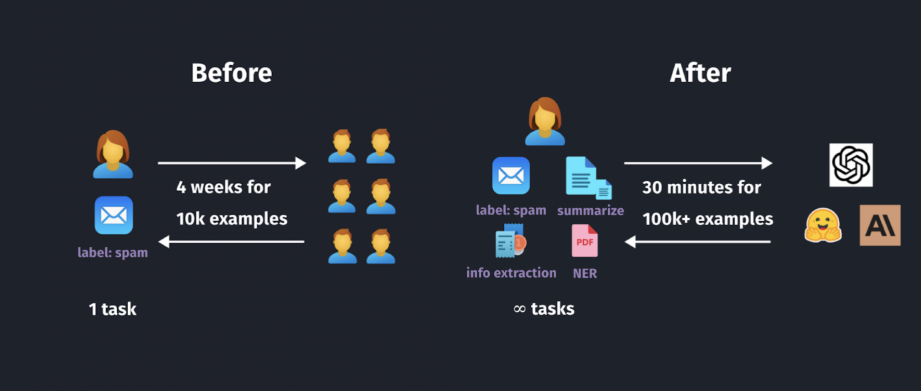
Autolabel终结人工标注!AI标注比人类标注效率高100倍
最近,一家初创公司refuel上线了一个AI标注数据的开源工具Autolabel,它能够利用LLM(如GPT-4等)自动对数据进行标注,大大简化了数据标注流程。与人工标注相比,Autolabel可将标注效率提高100倍,而成本仅为人工成本的1/7。
要点:
1、开源工具Autolabel能用LLM代替人工高效标注数据,效率提升100倍,成本仅1/7。
2、Autolabel支持主流LLM,可快速标注NLP数据集,准确率高达88.4%,超过人工标注。
3、Autolabel可估计标注置信度,不同LLM可平衡成本与质量,大幅降低标注门槛。
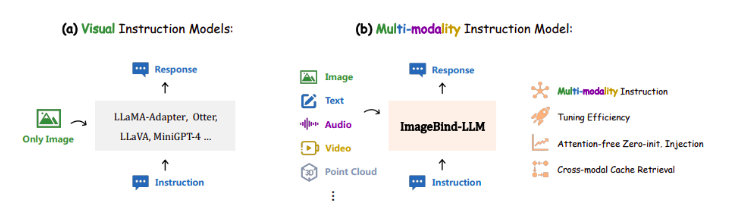
中国研究人员推ImageBind-LLM:通过ImageBind实现LLM的多模态指令调优方法
中国研究人员最近提出ImageBind-LLM方法,通过ImageBind实现了大型语言模型的多模态指令调优,提高了其响应多种输入指令的能力。
项目网址:https://github.com/OpenGVLab/LLaMA-Adapter
论文网址:https://arxiv.org/abs/2309.03905
要点:
1. ImageBind-LLM支持图片、文本、音频、3D和视频等多种模式的指令输入。
2. 使用高效的调优方法,如图像编码器冻结和参数高效技术。
3. 提出基于图像特征的视觉缓存模型,用于增强不同模态间的嵌入表示。
Calvin Wong开发首个设计师主导的AI系统AiDA
时尚创新者Calvin Wong开发了首个AI设计师助手AiDA,它能识别设计元素提供修改建议,但强调AI的目的是激发设计师创造力,而非取代人类。

要点:
1. AiDA是首个由设计师主导开发的AI系统,可以显著加速设计从草图到成品的过程。
2. AiDA通过图像识别提供设计修改建议,但Calvin Wong强调其目的是“促进设计师创作”,而非“取代设计师”。
3. AI在时尚设计领域应用带来个性化体验、专业化设计工具和可持续性进步等变革。
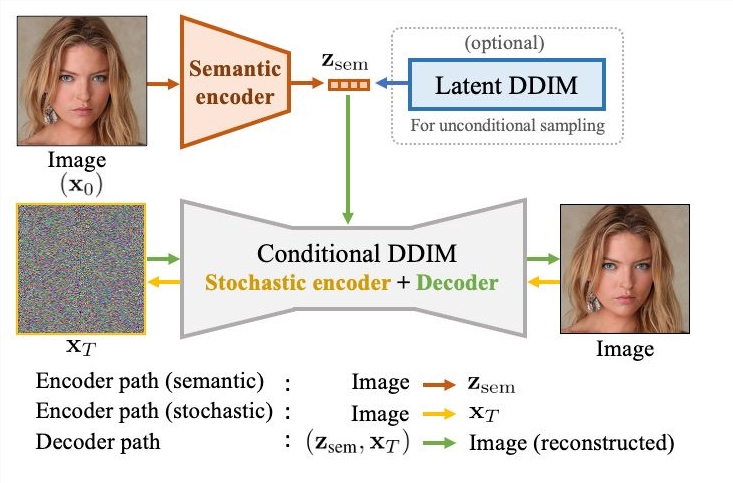
AI修改肖像模型DiffAE :可随意改变性别、年龄、表情、妆发等
DiffAE是一款强大的人工智能模型,能够实现图像到图像转换,可实现人像的年龄、性别、表情、妆发等方面的改变。DiffAE模型采用语义编码器结合条件DDIM,实现人像图像多方位的编辑转换。
要点:
1. DiffAE模型包含语义编码器与DDIM两部分,前者抽取图像高层特征,后者关注细节变化。
2. 模型可实现人像的年龄、性别、表情、妆发等多样化改变。
3. 应用范围广泛,可为创意设计、素材制作等领域提供支持。
智源开源中英文语义向量模型训练数据集MTP
智源研究院发布了一个包含3亿中英文文本对的大规模数据集MTP,这是全球最大的开源中英文语义向量模型训练数据集,旨在解决中文模型训练数据不足的问题。
MTP数据集链接:
https://data.baai.ac.cn/details/BAAI-MTP
BGE 模型链接:
https://huggingface.co/BAAI
BGE 代码仓库:
https://github.com/FlagOpen/FlagEmbedding
要点:
1. MTP数据集包含1亿条中文记录和2亿条英文记录,是目前最大的开源中英文关联文本对数据集。
2. MTP综合多种数据源,包括各类开源数据集、网络数据等,丰富了训练数据。
3. 作为中国代表机构,智源持续开源大模型全栈技术,推动AI领域技术创新和协同发展。
斯坦福大学推出Spellburst 可简化艺术创意转化为代码的过程
斯坦福大学的研究人员推出了Spellburst工具,利用GPT-4语言模型,可以让艺术家通过语义输入创作代码,改进创意构思和编辑过程。
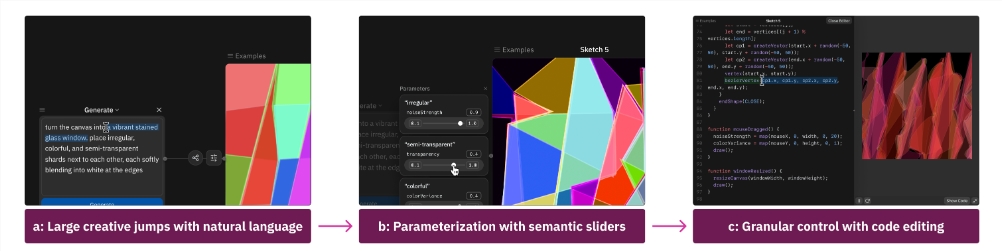
论文地址:https://arxiv.org/pdf/2308.03921.pdf
要点:
1. Spellburst让艺术家以语义方式编辑作品,GPT-4生成对应的代码。
2. 工具包含语义编辑面板,艺术家可以调整生成图像的各个方面。
3. Spellburst帮助艺术家从语义空间更快地过渡到代码空间,提高创作效率。
开源机器学习库vLLM 提升大语言模型推理速度
开源机器学习库vLLM通过PagedAttention算法和服务系统设计,在不改模型架构的前提下将大语言模型推理速度提升24倍,为降低LLM在实际应用中的部署成本提供了重要途径。
项目地址:https://github.com/vllm-project/vllm
论文地址:https://arxiv.org/abs/2309.06180
要点:
1、PagedAttention注意力算法通过采用类似虚拟内存和分页技术,可有效管理LLM推理中的关键值缓存内存。
2、vLLM服务系统几乎零浪费关键值缓存内存,内部和请求之间灵活共享缓存,大大提升吞吐量。
3、配备PagedAttention的vLLM相比HuggingFace Transformers提升了24倍吞吐量,无需改变模型架构,重新定义了LLM服务的最佳水准。
🤖📱💼AI应用
韩国互联网巨头NAVER发布大型艺术绘画模型DreamStyler
韩国互联网巨头NAVER子公司NAVER WEBTOON AI最近发布大型艺术绘画模型DreamStyler,能通过文字或图像实现不同艺术家风格的绘画转换,是数字艺术创作者的重要工具。

要点:
1. DreamStyler可以模仿梵高、毕加索等艺术大师的绘画风格。
2. 通过训练学习不同艺术风格的特征和转换规则。
3. 用户输入图像后可实现风格转换,为数字创作提供更多灵感。
“装逼”神器!BeFake允许你发AI“造假图”
一款名为“BeFake”的新应用推出,它被称为真人社交应用“BeReal”的“反面教材”,允许用户编辑并分享虚假的生活照片。
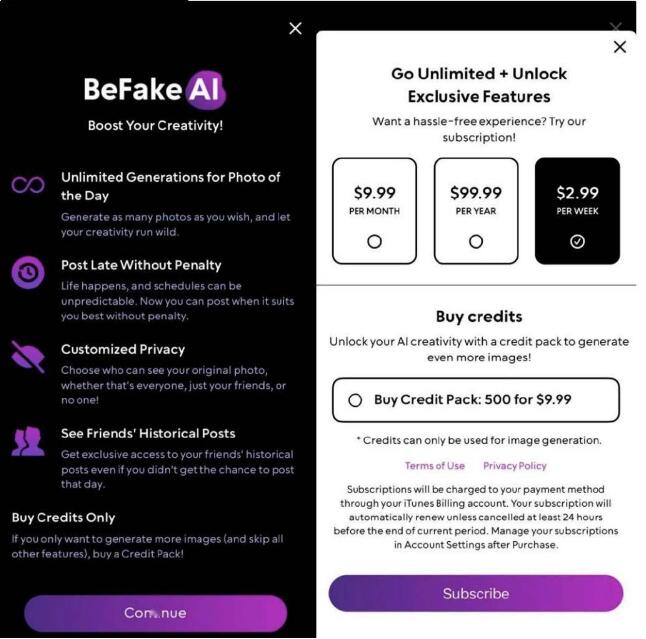
要点:
1. BeFake允许用户编辑照片呈现虚假生活,满足社交平台吹嘘需求。
2. 应用方式类似BeReal,不同是上传的照片经过虚假修饰。
3. BeFake满足用户在社交网络上获得认可和赞美的心理需求,反映用户渴望在网上比阔气。
Suno AI推文本到音乐模型Chirp v1可根据风格和歌词生成音乐
Suno公司最新推出Chirp v1文本到音乐模型,可以根据风格和歌词提示生成不同风格的音乐。它最大的改进是v1可以将流派(如摇滚、流行、韩流等)和描述(如旋律或快节奏)转化为音乐。

要点:
1. Chirp v1可以根据流派和描述生成匹配的音乐,支持用[verse] [chorus]分段提示。
2. Chirp集成在Discord中,提供每月250个免费credit,还可购买更多生成次数。
3. 目前英语和摇滚表现最好,歌词内容和结构会影响生成效果。
AI音乐创作助手Soundful 提供各种风格的音乐模板
Soundful是一个一站式音乐创作助手,它提供各种风格的音乐模板,使音乐创作变得简单,只需点击按钮就能创作出专业水准的原创音乐。
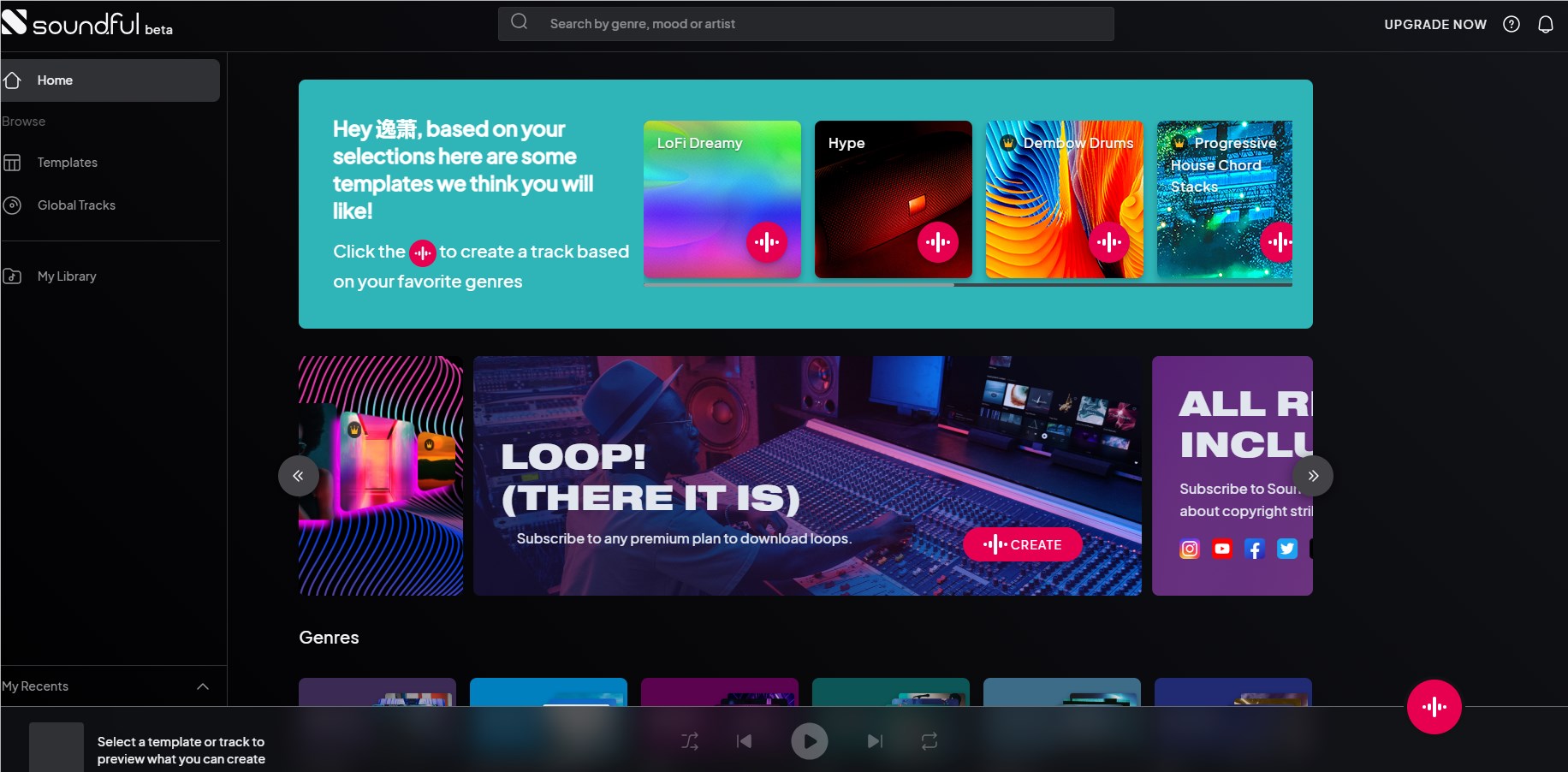
体验地址:https://my.soundful.com/
要点:
1. Soundful提供海量高品质音乐创作模板,涵盖多种流派风格。
2. 提供大量可自由组合的鼓组、乐器、音效等音乐素材。
3. 简单易用的在线音乐创作界面,一键导出高品质音频文件。
面部换脸应用Reface 只需一张自拍就能将你植入视频中
Reface是一款使用人工智能技术实现面部换脸的移动应用,用户只需上传一张自拍照,就可以将视频或GIF动图中的人脸替换成自己,实现身临其境的沉浸式体验。
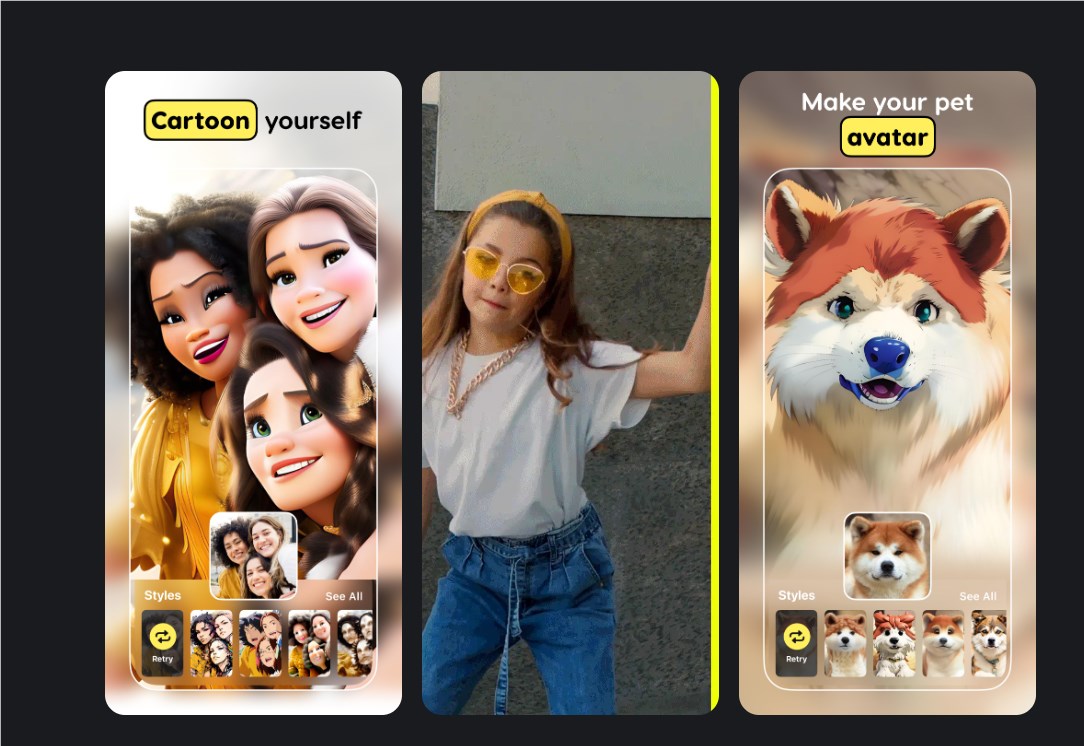
使用地址:https://reface.ai/
要点:
1. Reface应用了领先的人工智能算法,实现高质量逼真的面部换脸效果。
2. Reface拥有简单易用的移动应用界面,整个换脸过程只需要几秒钟。
3. Reface为大量用户提供稳定流畅的人工智能计算服务,可以同时处理海量面部换脸任务。
AI提示语:一个支持AI聊天、AI绘画的多功能平台
AI提示语是一个集成AI聊天、AI绘画等功能的人工智能平台,提供丰富的AI模型、可视化应用构建器、大量免费应用和多端支持,旨在帮助用户轻松创建和使用AI应用。
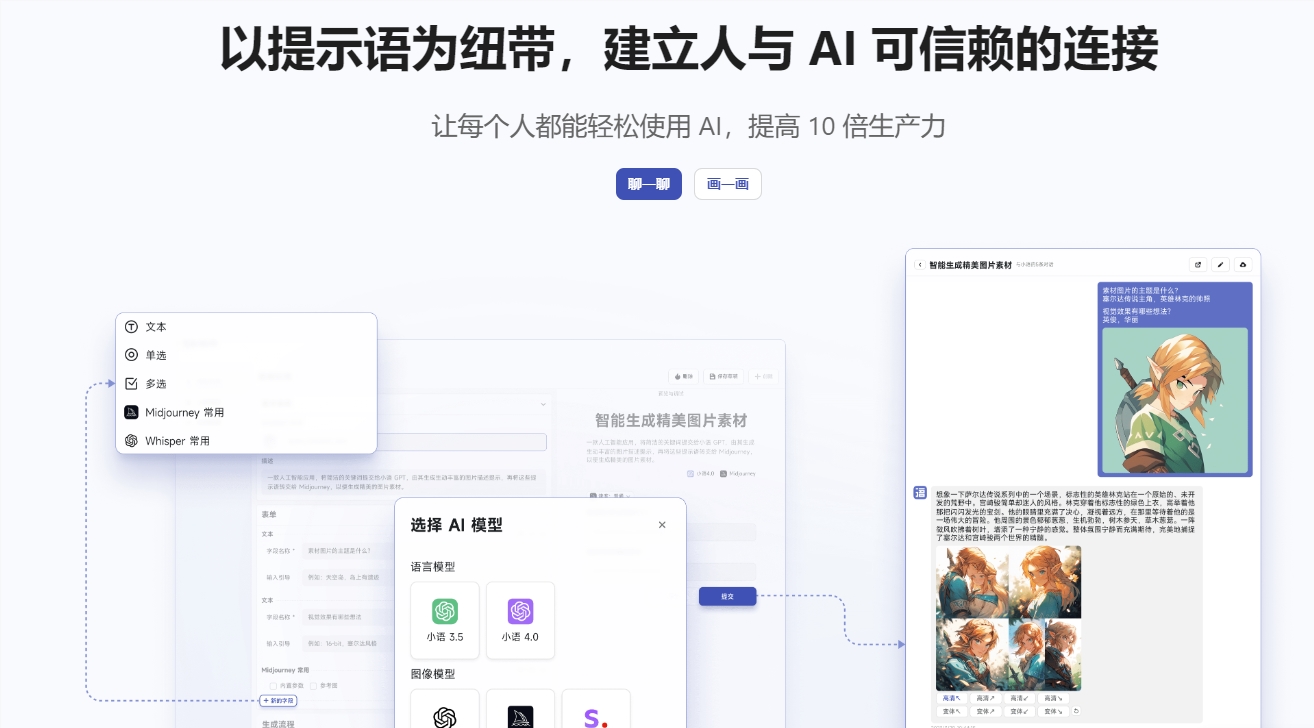
体验地址:https://www.tishi.top/
要点:
1. AI提示语提供语言、图像等各类领先AI模型,用户可以轻松调用实现不同需求。
2. 通过可视化拖拽构建器,用户可以无需编码快速创建自己的AI应用。
3. AI提示语拥有大量免费高质量应用,还支持网页、App、小程序等多端使用。
🤖📈💻💡大模型动态
万兴科技发布百亿级参数多媒体大模型 “天幕”
在2023世界计算大会上,万兴科技宣布将发布国内首个以视频创意应用为核心的百亿级参数多媒体大模型“天幕”,提供更专业化的AI创新解决方案,涵盖视觉、音频、语言等多模态AI生成和优化的能力。

要点:
1、万兴科技在计算大会上宣布发布“天幕”百亿级多媒体大模型,以视频为核心应用场景。
2、“天幕”具备一键成片、AI美术设计等多种核心功能,提供专业化的AI创新解决方案。
3、除“天幕”外,万兴科技还展示了多款嵌入大模型能力的AI创新应用产品。
日本政府与科技巨头联手投资数亿美元开发日语语言模型
日本政府与主要科技公司投资数亿美元,致力于开发超越ChatGPT的文化敏感日语语言模型。该模型将在国家超级计算机上训练,计划明年以开源形式发布,参数规模超过300亿。为评估模型对日本文化的适应性,研究人员开发了Rakuda排名系统,GPT-3.5在排名中表现最好。
要点:
1. 日本政府与科技公司投资数亿美元,开发文化敏感日语语言模型
2. 模型将在国家超级计算机上训练,明年以开源形式发布,参数超过300亿
3. 开发Rakuda排名系统评估模型对日本文化的适应性,GPT-3.5排名第一
 0000
0000
 0000
0000- 0000
- 0000
- 0000

