开源机器学习库vLLM 提升大语言模型推理速度
要点:
1、PagedAttention 注意力算法通过采用类似虚拟内存和分页技术,可有效管理LLM推理中的关键值缓存内存。
2、vLLM服务系统几乎零浪费关键值缓存内存,内部和请求之间灵活共享缓存,大大提升吞吐量。
3、配备PagedAttention的vLLM相比HuggingFace Transformers提升了24倍吞吐量,无需改变模型架构,重新定义了LLM服务的最佳水准。
近年来,大语言模型在改变人们的生活和职业方面影响越来越大,因为它们实现了编程助手和通用聊天机器人等新应用。但是,这些应用的运行需要大量硬件加速器如GPU,操作成本非常高。针对此,研究人员提出了PagedAttention注意力算法和vLLM服务系统,大大提升了LLM的推理吞吐量,降低了每次请求的成本。
PagedAttention将序列的关键值缓存分块,弹性管理不连续的内存空间,充分利用内存,实现内部和请求之间的缓存共享。配备PagedAttention的vLLM相比主流系统,在不改模型架构的前提下,提升了24倍吞吐量,达到了LLM服务的最佳水准。本研究为降低LLM在实际应用中的部署成本提供了重要途径。
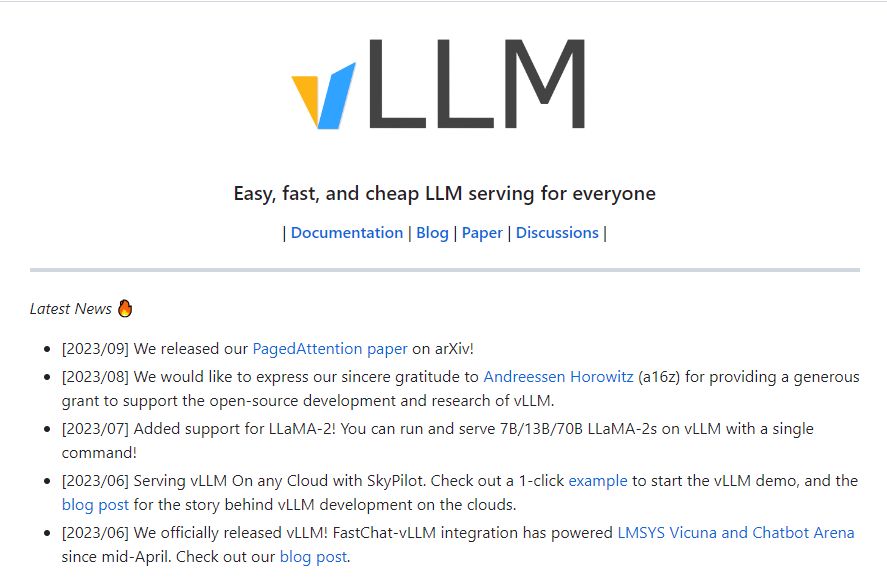
项目地址:https://github.com/vllm-project/vllm
论文地址:https://arxiv.org/abs/2309.06180
vLLM利用PagedAttention来管理注意力键和值。配备PagedAttention的vLLM比HuggingFace Transformers提供的吞吐量高出多达24倍,而无需对模型架构进行任何更改,这重新定义了LLM服务的当前最先进技术水平。
与传统的注意力算法不同,它允许在非连续内存空间中持续存储键和值。PagedAttention将每个序列的KV缓存分为块,每个块都包含了一定数量的令牌的键和值。这些块在注意力计算期间由PagedAttention内核高效识别。由于这些块不一定需要是连续的,因此可以灵活管理键和值。
内存泄漏只会发生在PagedAttention中序列的最后一个块中。在实际使用中,这导致了有效的内存利用率,仅有4%的微小浪费。这种内存效率的提高使GPU的利用率更高。
此外,PagedAttention还具有有效的内存共享的另一个关键优势。PagedAttention的内存共享功能大大减少了用于并行采样和波束搜索等采样技术所需的额外内存。这可以使采样技术的速度提高多达2.2倍,同时将内存利用率降低多达55%。这种改进使得这些采样技术对大型语言模型(LLM)服务变得更加有用和有效。
研究人员还研究了该系统的准确性。他们发现,与FasterTransformer和Orca等尖端系统相比,vLLM以与之相同的延迟增加了2-4倍的知名LLM的吞吐量。更大的模型、更复杂的解码算法和更长的序列会导致更明显的改进。
- 0001

 0000
0000- 0000
- 0000
- 0003