微软推出全新预训练模型phi-1.5 仅13亿参数常识推理碾压Llama2
站长网2023-09-18 10:01:440阅
要点:
1、微软研究人员推出了一个仅有13亿参数的LLM模型Phi-1.5。
2、Phi-1.5在常识推理任务上表现优异,优于多个参数量十倍以上的模型。
3、研究表明,模型参数规模不是决定性因素,高质量数据更为重要。
微软研究人员最近在一篇论文中提出了一个新的语言模型Phi-1.5,该模型的参数量仅有13亿。研究人员主要关注Phi-1.5在常识推理方面的表现,因为这是对语言模型能力的重要考验。
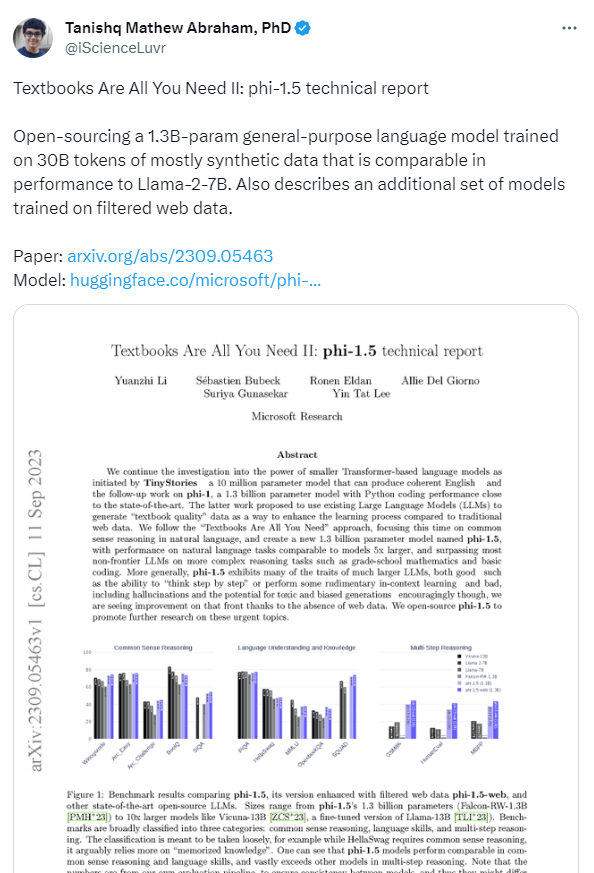
论文地址:https://arxiv.org/abs/2309.05463
项目地址:https://huggingface.co/microsoft/phi-1_5
结果表明,Phi-1.5在多个常识推理基准测试数据集上都取得了与参数量是其10倍以上的模型相当或更好的结果。例如在WinoGrande、ARC-Easy、ARC-Challenge、BoolQ和SIQA等数据集上的表现,都与Llama2-7B、Falcon-7B和Vicuna-13B相当甚至更好。
这说明模型的参数规模不是决定性因素,采用高质量合成数据进行预训练可能更为关键。研究中,Phi-1.5使用了微软之前提出的Phi-1模型的训练数据,以及新增的“教科书级”合成数据进行训练。
结果表明,Phi-1.5不仅展现出许多大模型所具有的语言理解和推理能力,在控制有害内容生成方面也具有一定优势,这对研究大型语言模型的社会影响意义重大。本研究表明,相比单纯追求模型规模,如何获取高质量训练数据可能更为重要,这为未来语言模型研究提供了新的思路。
0000
评论列表
共(0)条相关推荐
- 0000
- 0000
- 0000
- 0000

 0000
0000