智源开源中英文语义向量模型训练数据集MTP
站长网2023-09-18 09:26:030阅
近日,智源研究院发布面向中英文语义向量模型训练的大规模文本对数据集MTP(massive text pairs)。
这是全球最大的中、英文文本对训练数据集, 数据规模达3亿对,希望推动解决中文模型训练数据集缺乏问题。
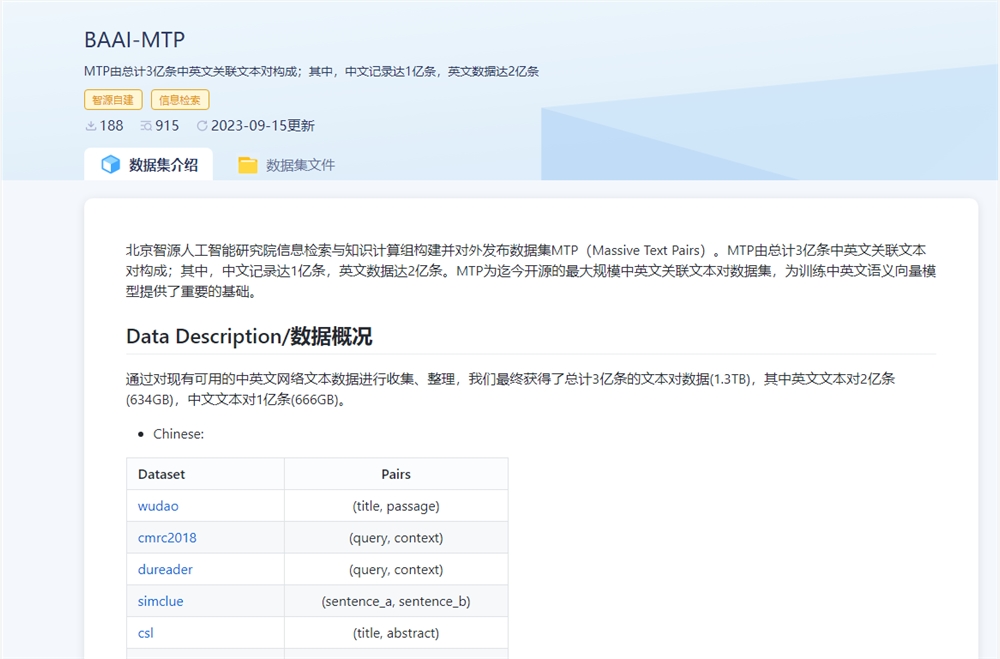
据介绍,MTP(massive text pairs)中文记录达1亿条,英文数据达2亿条。MTP 是目前为止开源的最大规模中英文关联文本对数据集,为训练中英文语义向量模型提供了重要的基础。
该数据集包含了各种不同的数据源,包括 wudao、cmrc2018、dureader、simclue、csl、amazon_reviews_multi、wiki_atomic_edits、mlqa、xlsum 以及其他一些来自互联网的数据,如社区问答、新闻和文献等。
智源研究院表示,数据对大模型训练起着至关重要的基础作用,开源亦是人工智能发展的关键推动力量。作为中国大模型开源生态圈的代表机构,智源持续进行包括数据在内的大模型全栈技术开源,推动人工智能协同创新。
MTP数据集链接:
https://data.baai.ac.cn/details/BAAI-MTP
BGE 模型链接:
https://huggingface.co/BAAI
BGE 代码仓库:
https://github.com/FlagOpen/FlagEmbedding
0000
评论列表
共(0)条相关推荐


 0000
0000

 0002
0002- 0000
- 0000
- 0000


