GPT-4 遭投诉要求禁用,OpenAI 为何成为众矢之的?
ChatGPT、GPT-4的迅速“出圈”,让 OpenAI 一战成名,外界对这家公司的关注度达到了前所未有的高度。
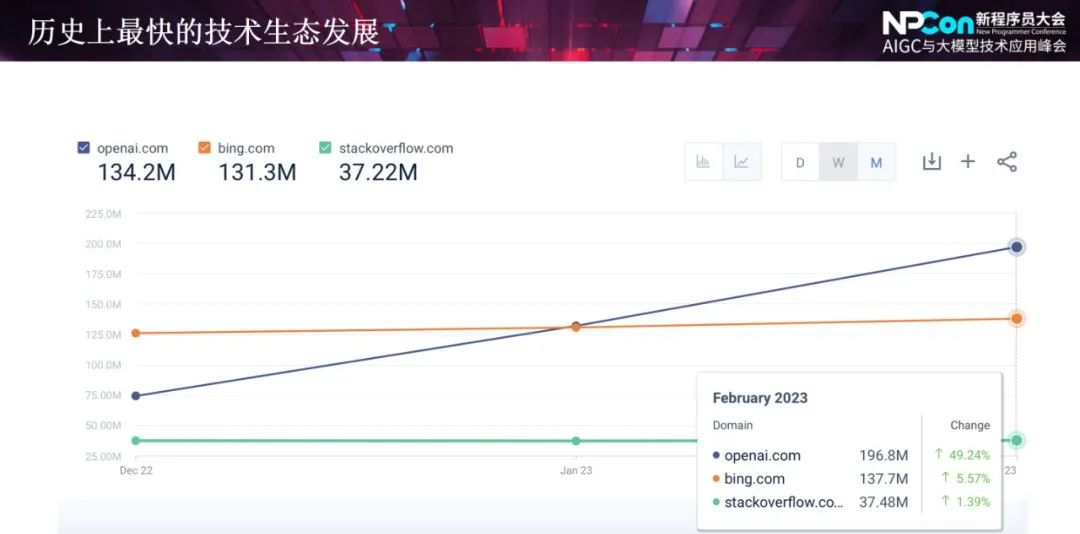
然而,欲戴王冠,必承其重。在如此前沿的技术到来之际,很多人将目光从技术本质的探索延展到道德、风险评估等维度。不久之前,CSDN 也曾报道过,非营利性的 "生命的未来研究所"(Future of Life Institute)发出一封公开信,以 LLM(Large Language Model)模型对社会和人类存在不可控的风险为由,呼吁全球所有的 AI 实验室都要暂停训练比 GPT-4更强大的系统,期限为六个月。包括图灵奖得主 Yoshua Bengio、伯克利计算机科学教授 Stuart Russell、特斯拉 CEO 埃隆·马斯克、苹果联合创始人 Steve Wozniak 等在内的数千名对人工智能领域关注的学者、企业家、教授都在这封公开信上签署了自己的姓名。
虽然尚未直接点名,但是众人心中都有数,能以最快速度训练出比GPT-4更强大系统的公司屈指可数,OpenAI 必在榜单的前列。
所以这一封信究竟是为了阻止 OpenAI 加速前进的步伐,还是真的担心 LLM 带来的弊会大于利,在业界尚未有统一的判定之前,因为这封信引发的舆论再次发酵,形成了两派:
一派,认为 “具有人类竞争智能的人工智能系统会对社会和人类构成深刻的风险”,甚至又有非营利机构要求美国政府部门联邦贸易委员会 FTC 出面调查 OpenAI,阻止 GPT-4的商用;

另一派则认可 LLM 对社会带来的真实改进和帮助,不能因部分人的顾虑而停止整个技术行业的发展。
那么,在两派的争论中,最终 LLM 的研发将何去何从?原本计划将在今年下半年推出的 GPT-5是否会如期?LLM 带来的真实风险又有哪些?
支持派:停止训练比 GPT-4更强的模型
“只有当我们确信它们的影响是积极的并且它们的风险是可控的时候,才应该开发强大的人工智能系统。因此,我们呼吁所有 AI 实验室立即暂停训练比 GPT-4更强大的 AI 系统,至少6个月。这种暂停应该是公开的和可验证的,并且包括所有关键参与者。如果不能迅速实施这种暂停,政府应介入并暂停“,公开信写道。
同时,其指出,「人工智能实验室和独立专家应利用这次暂停期,共同制定和实施一套先进的人工智能设计和开发的共享安全协议,并由独立的外部专家进行严格的审计和监督」。
当然,信中也澄清说,“这并不意味着总体上暂停 AI 开发,只是从越来越大且不可预测的黑盒模型的危险竞赛中退后一步。”
与此同时,据外媒 vice 报道,本次公开信发起者、图灵奖得主 Yoshua Bengio 表示,“民主价值观与这些工具的开发方式之间存在冲突”。
麻省理工学院 NSF AI 人工智能与基础交互研究所(IAIFI)物理学教授、未来生命研究所所长 Max Tegmark 认为,任由 AI 大模型继续训练下去,最坏的情况是人类将逐渐失去对文明越来越多的控制权。他表示,当前的风险是“我们失去了对科技公司中一群未经选举的人的控制,他们获得了巨大的影响力。”
事实上,微软、Google 等大型科技公司之间早已拉起 AI 军备竞赛,他们在过去的一年里发布了很多新的人工智能产品。
不过,这种频繁的发布节奏引起了公愤。继公开信之后,就在昨日,另一家非营利性研究机构人工智能和数字政策中心(Center for AI and Digital Policy,CAIDP)将状告到了美国政府部门。
他们要求联邦贸易委员会(简称 FTC)调查 OpenAI,声称这家新贵公司发布了 GPT-4,违反了商业法,同时他们认为该产品具有欺骗性并将人们置于危险之中。
CAIDP 表示,"FTC 已经宣布,人工智能的使用应该是'透明的、可解释的、公平的、有经验的,同时促进问责制',不过 OpenAI 推出了一个有偏见、有欺骗性、对隐私和公共安全有风险的产品。现在是 FTC 采取行动的时候了。”
他们还批评了 OpenAI 在其模型和训练数据方面没有实现透明。CAIDP 也敦促 FTC 对 OpenAI 展开调查,要求禁止 OpenAI 所有基于 GPT 产品的进一步商业部署,对其技术进行独立评估,并确保其符合联邦贸易委员会的规则,才能重新上市。
反对派:不能停止未来 GPT-5以及更强模型的训练
虽然 OpenAI 自身也承认 GPT-4并不完美,仍然会对事实验证的问题产生错乱感,也会犯一些推理错误,还偶尔过度自信,甚至连 OpenAI CEO Sam Altman 在接受外媒采访时也曾表示过,公司对人工智能的潜力感到“有点害怕”。
不过,Sam Altman 表示,这是“好事”,人工智能可能会取代许多工作,但它也可能会带来“更好的工作”。
而对于这封公开信的呼吁,诸多 AI 专家持反对意见。
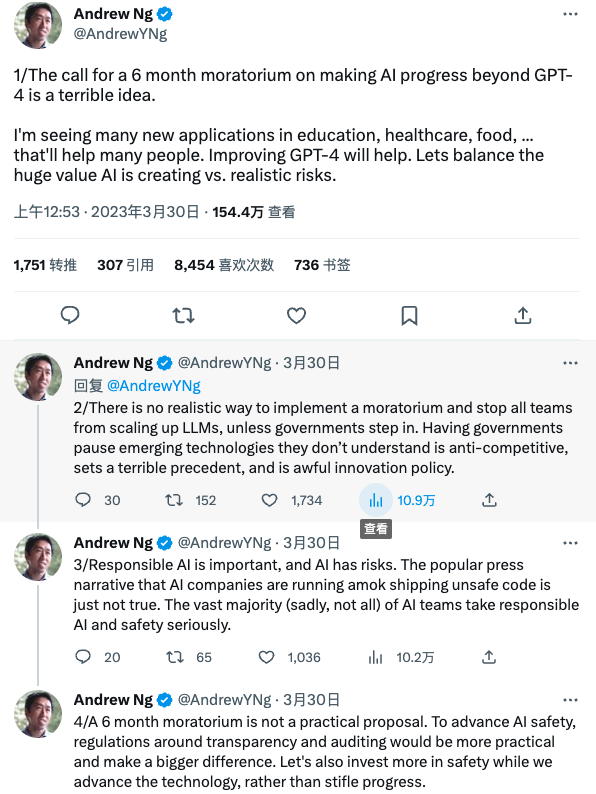
前谷歌大脑成员、在线教育平台 Coursera 创始人吴恩达连发四条推文,强烈反对「暂停计划」。他表示:
呼吁在6个月内暂停训练比 GPT-4更强的模型是一个可怕的想法。
我在教育、医疗、食品......方面看到了许多新的应用,这将帮助许多人。改进 GPT-4将是有实质价值的。让我们平衡一下人工智能正在创造的巨大价值与现实的风险。
除非政府介入,否则没有现实的方法来实施暂停令,阻止所有团队扩大 LLM 的规模。不过,让政府来暂停他们不了解的新兴技术是反竞争的,树立了一个可怕的先例,是糟糕的创新政策。
负责任的人工智固然重要,不过,人工智能也有风险。媒体普遍认为,人工智能公司正在疯狂地输出不安全的代码,这不是事实。绝大多数(可悲的是,不是所有)人工智能团队都在认真对待负责任的人工智能和安全研究。
6个月的暂停期并不是一个实用的建议。为了促进人工智能的安全,围绕透明度和审计的法规将更加实用,并产生更大的影响。在推动技术发展的同时,让我们也对安全进行更多的投资,而不是扼杀进步。
也有人工智能专家批评这封信进一步推动了“人工智能炒作”周期,而不是直接列出或呼吁针对当今 LLM 存在的风险采取具体的行动。
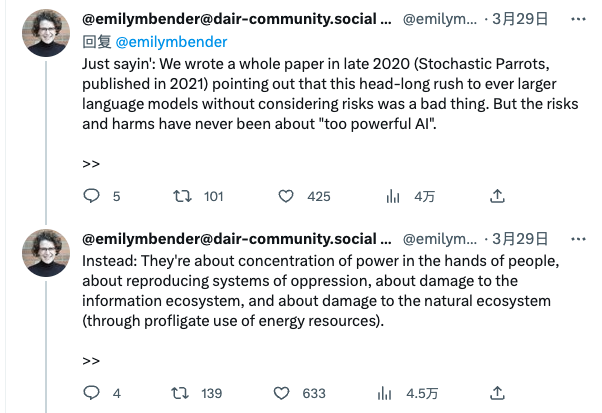
华盛顿大学语言学系教授、公开信中引用的第一篇论文的共同作者 Emily M. Bender 在推特上表示,「这封公开信 "掺杂了#Aihype"」,信中滥用了她的研究。
公开信指出,"正如大量研究表明的那样,具有人类竞争智能的人工智能系统会对社会和人类构成深刻的风险。"
不过,Bender 反驳说,"我们在2020年底写了一篇论文(《随机鹦鹉》,2021年发表),指出这种不考虑风险就一头扎进越来越大的语言模型的做法是一件坏事。但风险和危害从来都不是关于'太强大的人工智能'本身,相反:它们是关于权力集中在人的手中,关于压迫制度的再现,关于对信息生态系统的损害,以及关于对自然生态系统的损害(通过对能源资源的暴殄天物)。"
Hugging Face 的研究科学家兼气候负责人 Sasha Luccioni 表示,“这(公开信)本质上是误导:让每个人都注意到 LLM 的假设权力和危害,并提出一种(非常模糊和无效的)解决方法,而不是此时此地正确看待风险并尝试解决这些问题——例如,在 LLM 出现时,可以要求相关企业对 LLM 的训练数据和能力实行更高的透明度,或有关何时何地可以使用它们进行立法。”
GPT-4以及后续更强的大模型为何成为众矢之的?
截至目前,OpenAI 联合创始人 Greg Brockman 倒是发了几条推文,声明了 GPT-4模型的进步与立场。
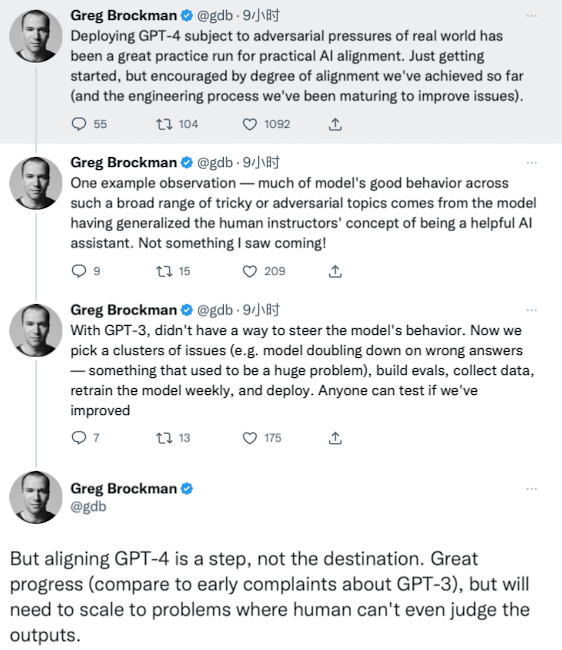
他表示,”在现实世界的对抗压力下部署 GPT-4是对实际 AI 对齐的一次伟大实践。虽然刚刚开始,但我们对迄今为止所取得的一致程度备受鼓舞(以及我们为改善问题而不断成熟的工程流程)。“
Greg Brockman 说,可以通过一个例子观察到,模型在如此广泛的棘手或对抗性话题中的良好行为,大部分来自于模型已经概括了人类导师的概念,即成为一个有帮助的人工智能助手。
「在 GPT-3中,它没有办法控制模型的行为。现在,我们选择一组问题(例如,模型在错误的答案上频率非常高——这曾经是一个巨大的问题),可以建立评估,收集数据,每周重新训练模型,并进行部署。任何人都可以测试我们是否已经改进。
但是对齐 GPT-4只是其中一个环节,而不是终点。这已经实现了很大的进步(与早期对 GPT-3的抱怨相比),但需要进一步扩展到人类甚至无法判断输出的问题。」
其实,在 OpenAI 官方博客上,该公司也一直强调,AI 需要对齐,「对齐研究旨在使人工智能(AGI)与人类价值观保持一致并遵循人类意图」。
不过,OpenAI 的发声并未获得一些激进派的认可,而 OpenAI 之所以深陷舆论漩涡,或有两方面的原因:
一是 LLM 技术发展速度超出了很多人的意料,其中相关的法律法规、道德与使用等规范制度还存在很大的缺失。
正如早些时候,Deepmind 研究团队在借鉴了计算机科学、语言学和社会科学的多学科文献基础上发布的《语言模型危害的伦理和社会风险》论文中写道的那样,LM 会存在歧视、仇恨言论和排斥;信息泄露;虚假信息;恶意使用;人机交互;环境和社会经济等多重危害。
因此,如何降低这些潜在危害,作为行业领头羊的 OpenAI 必须要弄清楚,因为它的很多动作也是后来者参考的目标。然而,现实来看,这也并不是 OpenAI 公司一家所需要考虑的事情,而是需要 AI 的所有参与者共同来制定。
二是 OpenAI 树大招风,尤其是 GPT-4不透明性引发了很多人的不满。
自 ChatGPT、GPT-4发布以来,已经很多人批评过「OpenAI 不再 Open」了。不久前,Nomic AI 信息设计副总裁 Ben Schmidt 在推特上直指,OpenAI 在发布 GPT-4技术的98页论文中,丝毫没有提及关于训练集内容的任何信息。

也有网友称,OpenAI 正在”假装“开放。

不过,对于 LLM 究竟是应该开源还是闭源,又是一个引发争议的问题。针对这一点,据外媒 The Verge 报道,OpenAI 首席科学家、联合创始人 IlyaSutskever 在接受采访时也曾回应过,「OpenAI 不分享关于 GPT-4的更多信息的原因是“不言而喻的”——害怕竞争和对安全的担忧。」
Sutskever 表示,“在竞争格局方面--外面的竞争很激烈。GPT-4的开发并不容易。几乎 OpenAI 的所有人在一起花了很长时间才做出了这个东西,而且(目前)有很多很多公司都想做同样的事情。
安全方面,我想说,还没有竞争方面那么突出。但它将会改变,基本上是这样的。这些模型非常强大,而且会变得越来越强大。在某种程度上,如果有人想的话,很容易用这些模型造成很大的伤害。随着(模型)能力的增强,你不想透露它们是有道理的。”
虽然从商业的角度,OpenAI 不公开大模型架构(包括模型大小)、硬件、训练计算、数据集构建、训练方法等细节合乎情理,但是也有人表示,不公开训练数据,很难知道该系统可以在哪里安全使用并提出修复方案,不利于大模型的研究。
为此,你是否支持暂停更强大模型的训练?你认为大模型是开源好,还是闭源好?欢迎留言分享你的看法。
参考资料:
https://cdn.arstechnica.net/wp-content/uploads/2023/03/CAIDP-FTC-Complaint-OpenAI-GPT-033023.pdf
https://futureoflife.org/open-letter/pause-giant-ai-experiments/
https://www.vice.com/en/article/qjvppm/the-open-letter-to-stop-dangerous-ai-race-is-a-huge-mess
https://www.theverge.com/2023/3/15/23640180/openai-gpt-4-launch-closed-research-ilya-sutskever-interview
- 0000
- 0000
 0000
0000- 0000
- 0002