在OpenAI引领的多模态时代,专注语音的ElevenLabs如何生存?
2024年2月,OpenAI的视觉大模型Sora横空出世,这是一个历史性的里程碑,视觉生成领域将有一次大的技术和商业革命。
在Sora发布几天后,AI语音创业公司ElevenLabs为Sora的演示视频完成了精准匹配的配音,AI视频“以假乱真”的制作链条实现了闭环。这些视频利用他们即将上线的AI Sound Effects功能制作,该功能可以让用户输入Prompt自动生成声音。
中国舞龙表演,敲锣打鼓人声鼎沸(视频:Sora,音频:ElevenLabs)
2022年创立的ElevenLabs在6个月时间内连续获得两轮融资,在2024年1月的8000万美元B轮融资中,它的估值增长了10倍,达到了11亿美元。
在A轮和B轮的两轮投资中,领投方都是a16z、前GitHub首席执行官Nat Friedman和前苹果人工智能领导者Daniel Gross。A轮的参投方包括Instagram联合创始人Mike Krieger、Oculus联合创始人Brendan Iribe、DeepMind及Inflection AI联合创始人Mustafa Suleyman;B轮投资的参投方包括SV Angel、红杉资本、BroadLight Capital和Credo Ventures。
ElevenLabs的联合创始人兼CEO Mati Staniszewski表示:“新融资将用于继续构建ElevenLabs尖端的声音人工智能研究中心,并推出一系列产品,以支持特定市场垂直领域,如出版、游戏、娱乐和对话应用。”
如果您对人工智能的新浪潮有兴趣,有见解,有创业意愿,欢迎扫码添加“阿尔法小助理”,备注您的“姓名 职位”,与我们深度连接。
来自波兰的创始人用文本-语音模型实现声音克隆
ElevenLabs由前谷歌机器学习工程师Piotr Dabkowski和前Palantir部署策略师Mati Staniszewski(CEO)在2022年创立,他们是童年的好友,出生和成长于波兰,都在英国完成了大学教育。其中Mati Staniszewski毕业于帝国理工大学,曾经两次创业,而Piotr Dabkowski的本科和硕士分别毕业于牛津和剑桥大学。
当新一轮AI浪潮萌芽时,他们决定一起创业,基于对儿时外国电影配音低劣质量的“痛苦回忆”,这对搭档决定搭建一个由人工智能驱动的高质量音频平台,于是ElevenLabs诞生了。
在初期阶段,ElevenLabs凭借文本到语音模型Eleven Multilingual引起大众注意,这个模型能合成听起来自然的英语AI声音。随后,该模型扩展到Eleven Multilingual v1和v2,引入了对更多语言的支持,包括波兰语、德语、西班牙语、法语、意大利语、葡萄牙语和印地语等。
同时,ElevenLabs还开发了一个产品—声音实验室,用户可以在其中克隆自己的声音或生成全新的合成声音(通过随机采样声音参数)。这使他们能够将自己选择的文本,如播客剧本,转换成他们偏好的声音和语言的音频内容。
ElevenLabs创始人Mati Staniszewski在接受采访时表示:“ElevenLabs的技术结合了上下文意识和高压缩技术,以提供超逼真的语音。该公司的专有模型不是一句句地生成语句,而是建立在理解单词关系的基础上,并根据更广泛的上下文调整语音输出。它也没有硬编码的特征,这意味着它可以在生成语音时动态预测数千种声音特征。”
根据Market US的数据,音频类工具的全球市场规模在2022年为12亿美元,预计到2032年将接近50亿美元,复合年增长率高于15.40%。
ElevenLabs具有AI时代创业公司的组织特征,在B轮融资时,它的团队仅包括40名远程工作人员,获得新融资后,他们计划将团队逐渐扩展到100人。
连续两轮领投ElevenLabs的投资机构a16z表示:“我们坚信生成式人工智能工具将彻底改变创意套件—通过让专业人士创作出更多高质量的内容,释放更多创造力,并且由于工具更易于使用、更直观,使得大量全新的创作者得以赋能。我们很高兴能加入ElevenLabs董事会,并与Nat Friedman和Daniel Gross共同领投他们。”
ElevenLabs创始人Mati Staniszewski总结道:“我们的雄心依然不变—通过打破语言和沟通障碍,改变我们与内容的互动方式。我们正在构建尖端技术,使内容跨越语言和声音,让每个人都能与重要的信息和故事建立联系。我们到目前为止的进展证明了我们敬业的团队和投资者的价值,虽然这仅仅是我们旅程的开始,但我们共同在塑造无障碍和沟通未来的道路。”
模型之外,可靠性和可控性是赢取客户的关键
对于影视,游戏,媒体等行业的开发者和创意工作者,将高质量的声音融入他们的作品一直是耗时且成本高昂的。
虽然文本转语音(TTS)技术已经存在了几十年,但是此前的技术合成的语音呆板且合成感重。想要获得个性化和清晰的语音,仍然需要专业设备,专业配音演员,例如大部分游戏设计师只能负担得起主要角色的配音演员,所以让非玩家角色保持沉默。
ElevenLabs致力于改变这一现状,通过其专有的语音合成、声音设计和克隆技术,让每个程序都拥有声音。通过几次点击,他们的先进语音AI基础模型能够生成听起来极其接近人声的语音,具有适当的停顿、语调和呼吸节奏。用户甚至可以从30秒的音频片段中克隆自己的声音。
Eleven Multilingual基础模型
ElevenLabs的技术基础是先进语音AI基础模型,它被命名为Eleven Multilingual,在2023年8月,它被升级到V2版本。ElevenLabs分析了人类语音的标记,构建了新的机制来理解上下文和在语音生成中传达情感,以及合成新的、独特的声音。
通过Eleven Multilingual v2,当文本输入到ElevenLabs的文本到语音平台时,新模型可以自动识别近30种书面语言,并以前所未有的真实性生成这些语言的语音。这些语言包括了世界上被使用最多的语言,当然也包括中文。
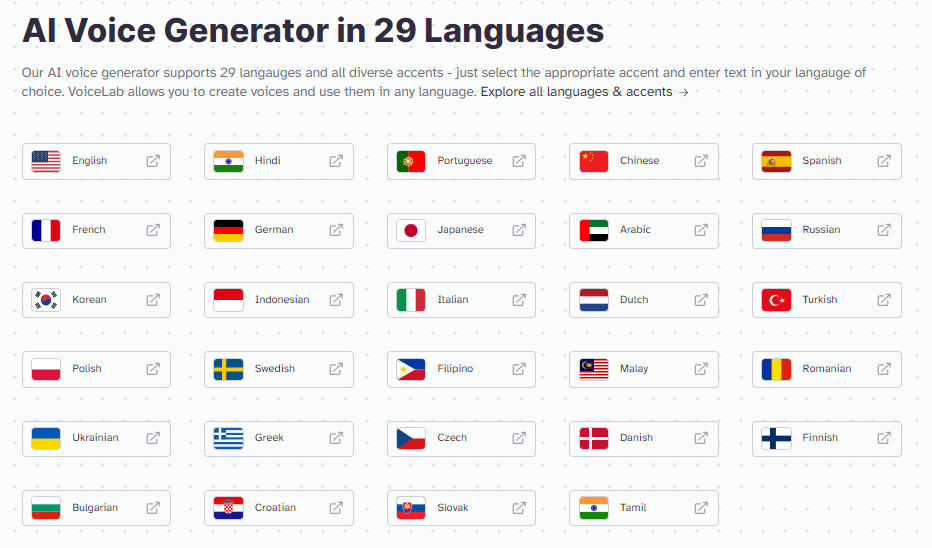
不但可以用文字生成语音,还可以语音生成语音
它的语音合成(SPEECH SYNTHESIS)产品包括一系列强大功能。
Text to Speech和Speech to Speech都是针对普通个人用户的,其中Speech to Speech是新推出的功能,它可以让用户在声音稳定性,声音清晰度和声音风格上进行调节。
在Voice Lab中声音克隆,仅需很短的样本,就能克隆用户的声音,并且很快就能听到结果。不过这是一个收费功能,它同样分个人版和专业版。
Projects则是一个针对专业用户和商业/机构用户的功能,它能够支持更长的文本和精确编辑,用户可以用它制作有声书等面向商业化的作品。目前这个功能的客户包括了Storytel、《华盛顿邮报》、莱茵邮报、Curio等。
Dubbing是与影视行业更贴近的,它能够自动为视频/音频配音,并能够快速翻译,因为Eleven Multilingual V2模型的能力,它能够支持29种语言。
针对更专业的用户,它还有Dubbing Studio,让用户可以对配音进行更精细的控制和制作。
针对企业客户,ElevenLabs也有自己的API,方便这些客户将AI音频能力嵌入自己的产品和应用中。例如此前我们详细介绍过的Inworld(请参考:融资5000万估值5亿美元,智能助手的先驱用AI让游戏NPC拥有情感和记忆|AlphaFounders),就利用ElevenLabs的产品为自己的AI NPC增添了声音功能,让玩家的沉浸感更强。此外,ElevenLabs也与电影制作人Nik Shaw合力打造动漫作品,与Y7联手制作科幻电影 。
客户与商业模式
ElevenLabs在商业化上是个人用户和企业客户两手抓的策略。
针对个人用户,它有免费的服务引流(目前已经有超过百万的注册用户),然后针对不同专业程度的个人用户收费,推出了Starter(每月1-5美元),Creator(每月11-22美元),Independent Publisher(每月99美元)三档收费。
针对企业用户,有Growing Business(每月330美元)和Enterprise(按需定制收费)。它会按照功能和用量来区分不同等级的会员。
在2023年,扩大了B2B方面的商业投入和合作。目前在出版、游戏、媒体和垂直对话式AI公司等领域积累了不少标杆客户。
出版领域:Storytel、《华盛顿邮报》、《莱茵邮报》、Curio
对话式AI:FlowGPT、SimpleTalk AI、Ollang、VoiceDrop、Vana
媒体与娱乐:Wondershare Filmora、Futuri Media、TheSoul Publishing
游戏行业:Paradox Interactive、网易、Inworld
用安全措施和语音库市场应对争议
ElevenLabs目前是AI音频领域的领头羊,它也面临着最大的争议,这争议主要来自两个方面。
第一是担心不法分子利用ElevenLabs的技术作恶,例如克隆名人的声音然后伪造视频或音频发布一些类似暴力威胁、种族主义等有争议的内容。而且目前ElevenLabs生成的声音也能通过银行的声音验证。
ElevenLabs对此的应对是引入一系列安全措施,例如将声音克隆限制在付费账户中,禁止反复违反其服务条款的用户。他们还一种新的AI检测工具,能够检测上传的音频样本中是否包含来自ElevenLabs的AI生成内容。
第二是有人担心ElevenLabs抢了配音演员的饭碗,就像好莱坞的演员担心被AI视频生成抢饭碗一样。ElevenLabs的应对是推出语音库市场(Voice Library marketplace)。
语音库市场为用户提供一个安全的平台,让他们能够从自己的 AI 版本声音中获得收入。用户可以创建他们的专业 AI 语音副本,进行验证,并通过语音库分享。当其他用户使用这些经过验证的声音时,原始创作者将获得报酬。
多模态模型和大公司会把ElevenLabs们拍在沙滩上么?
当OpenAI的GPT-4V出现后,各种多模态AI模型涌现,Sora的出现,也让越来越多的人认为多模态模型是走向AGI(通用人工智能)的正确道路。那么随着多模态模型支持的模态越来越多,单一模态的AI语音模型会不会失去存在的价值?
从技术上看,多模态可能比单一模态好,但是从商业上却不一定,因为单一模态在可控性和成本上会比多模态更好些(至少在近几年),这给了创业者们创业空间。
此外,AI语音虽然不像AI视觉那样“光鲜”,但它仍有众多的应用场景。例如影视配音(文首已经展示),游戏配音,有声书,新闻,播客,会议转录等。
所以ElevenLabs其实有不少竞争对手,例如Papercup、Deepdub、Acapela、Respeecher和Voice.ai等创业公司,以及Amazon和OpenAI这些领先公司。那么面对资金更充足,人才更集中的Amazon和OpenAI,ElevenLabs会被"拍在沙滩上"么?
领先的公司要在关键领域确保自己的领导地位,突破技术,建立平台,也会做垂类应用,但更重视吸引广大开发者参与,而不是有点突破就摊大饼,把应用都做完。这一点,在之前的文章中就分析过(请参考:ChatGPT创业:狮子和土狼一起奔向光明|投资人说)。
ElevenLabs有自己的模型,有针对个人和大公司的产品,还有语料库市场经营生态。目前AI的商业格局还未定局,这种既掌握底层技术又拥有商业场景的公司,会在未来的发展中拥有自己的一席之地。
- 0000
- 0000
 0000
0000
 0000
0000- 0001


